
[Network] XML DOM Parser 동작 방식 정리
XML
- 일단 “XML이란 무엇일까?”에 대해 생각해 보기 위해 gist에 커밋을 하기 위해 인텔리제이를 켰다.
- 위 사진을 보면 gitignore 파일에 .xml이 포함되어 있어 xml 파일들은 unstaged 된 것을 알 수 있다.
- 왜 저 XML 파일들은 생겨났고, 또 어떨 때 사용되는지가 너무 궁금했다.
- XML은 “ eXtensible Markup Language”로, 확정될 수 있는 표시 언어로 불린다.
- Markup Language로는 HTML이 있다
- XML과 HTML로 예를 들어 XML을 설명할 수 있다.
- 이 둘은 같은 Markup Language이기 때문에 생긴 건 비슷하지만, 큰 차이점이 존재한다.
- HTML의 태그: 이미 약속한 태그들만 사용 가능
- XML의 태그: 사용자 임의로 만들 수 있음
- 이 둘은 같은 Markup Language이기 때문에 생긴 건 비슷하지만, 큰 차이점이 존재한다.
- 그렇다면 XML의 태그는 왜 사용자가 임의로 만들었는지 생각을 해봐야 한다.
- XML은 어떠한 데이터를 설명하기 위해 이름을 임의로 지은 태그로 데이터를 감싼다.
- 즉, 태그로 데이터 설명을 한다.
- 이 부분에서 데이터 표시(Markup)가 된다.
- 더 필요한 데이터가 생길 시, 태그 추가 혹은 태그 안의 내용을 추가할 수 있다는 특징이 있다. (Extensible)
- 즉, 태그로 데이터 설명을 한다.
- XML은 어떠한 데이터를 설명하기 위해 이름을 임의로 지은 태그로 데이터를 감싼다.
- 예시는 아래와 같다.
<?xml version="1.0"?>
<컴퓨터언어>
<C언어>C</C언어>
<C언어>C++</C언어>
<C언어>C#</C언어>
<JAVA>java</JAVA>
<JAVA>android</JAVA>
</컴퓨터언어>
<컴퓨터언어>라는 태그 아래 C언어 태그와 JAVA 태그가 있으며 각 태그에 맞는 메타 정보들이 배치되어 있다.- 이렇게 XML은 우리가 필요한 정보들을 받거나 줄 수 있는 데이터 형태를 제공해 준다.
- HTML로 위와 같은 정보를 작성한다면
- C, C++과 같은 메타 정보 등은 얻을 수야 있겠지만, 데이터를 설명해주는 정보는 없을 것이다.
- 즉, XML은 아래와 같이 정보들을 태그로서 마크하여 필요한 내용을 안에 적는 양식이다.
- 텍스트 기반이며 간결한 데이터형이다.
- 웹에서 디스플레이 표준을 HTML로 한 것처럼, 데이터의 표준으로 만들기 위한 노력이 있다.
- Markup Language(HTML)가 아니라 Markup Language를 정의하기 위한 언어이다.
- 자신의 어플리케이션에 적합하게 작성이 가능하다.
- 이때의 어플리케이션은 앱을 뜻하는 게 아니라 API(Application Programming interface)를 뜻한다.
- API는 컴퓨터 처리에 있어서 프로그래밍을 쉽게 해주는 인터페이스라 할 수 있다.
- 초보자를 위해 마이크로소프트 에서 XML에 대해 상세히 설명해두었으니 이 링크를 봐도 좋을 것 같다.
Parser
- 일련의 문자열을 의미 있는 토큰 단위로 분해하고, 이를 AST로 변환하는 과정을 Parsing이라고 한다.
tokenizer
- Text를 의미 있는 요소들인 토큰으로 쪼개는 것을 Tokenization이라 한다.
- Tokenization을 해주는 도구를 Tokenizer라고 한다.
- 이는 다양한 방법이 있으며, 그에 따라 다양한 Tokenizer가 존재한다.
- 따라서 어떤 데이터를 다루느냐에 따라 다른 Tokenizer를 이용하는 것이 좋다.
- 예를 들어,
"You know what? This is my code."라는 문장을['You', 'know', 'what', '?', 'This', 'is', 'my', 'code']와['you', 'know', 'what?', 'this', 'is', 'my', 'code']로 서로 다른 결과를 출력할 수 있다.
lexer
- lexical analysis의 약자로, 어휘 분석 도구이다.
- 토큰의 의미를 분석하는 역할을 한다.
- 가래 떡으로 예를 들었을 때 아래와 같이 생각해볼 수 있다.
- 기계에서 가래떡을 뽑아내다가(한글자씩 탐색하다가)
- 적당한 길이가 될 때(단어가 될 떄)
- 잘라낸다.
parser
- 입력 데이터를 가지고 그것을 구조적으로 나타낼 수 있게 해주는 도구이다.
- 또한, 이 입력 데이터가 올바른지 검증한다.
- 토큰화된 소스코드를 가지고 AST를 만드는 일을 한다.
- AST를 만들게 되면 컴퓨터가 이해할 수 있는 언어로 바꿀(compile) 준비가 끝나게 된다.
DOM
- 문서 객체 모델(Document Object Model)을 줄여서 DOM이라 부른다.
- DOM은 HTML 문서에 접근하기 위한 일종의 인터페이스이다.
- 이 객체 모델은 문서 내의 모든 요소를 정의하고, 각각의 요소에 접근하는 방법을 제공한다.
- 이러한 DOM은 W3C의 표준 객체 모델이며, 아래와 같이 계층 구조로 표현할 수 있다.
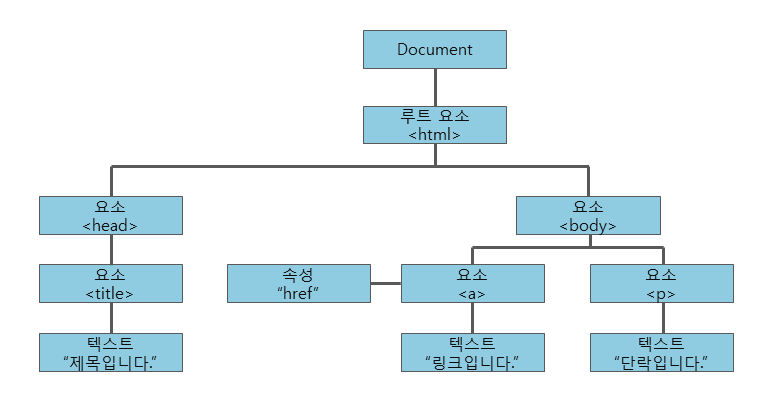
- W3C DOM 표준은 세가지 모델로 구분된다.
- Core DOM: 모든 문서 타입을 위한 DOM 모델
- HTML DOM: HTML 문서를 위한 DOM 모델
- HTML 문서를 조작하고 접근하는 표준화된 방법을 정의한다.
- 모든 HTML 요소는 HTML DOM을 통해 접근할 수 있다.
- XML DOM: XML 문서를 위한 DOM 모델
- XML 문서에 접근하여, 그 문서를 다루는 표준화된 방법을 정의한다.
- 모든 XML 요소는 XML DOM을 통해 접근할 수 있다.
- XML 문서 내의 모든 요소의 객체, 속성 그리고 메서드를 정의한다.
- 플랫폼이나 프로그래밍 언어에 상관없이 언제나 사용할 수 있다.
- XML DOM 관련해서도 마이크로소프트 에서 잘 정리해두었으니 참고하면 좋을 것 같다.
XML DOM Parser 동작 방식
- HTML은 암문적으로 태그에 대한 생략이 가능하는 등 문법이 너그롭기 때문에 파싱하기가 어렵다.
- HTML 파싱은 크게
토큰화와트리 구축두 단계로 이루어져 있다.
토큰화
<html>
<body>
Hello world
</body>
</html>
- 토큰화의 경우 어휘 분석으로서 연속된 문자를 입력받아
<를 만나면태그 열림 상태가 된다. - a-z까지의 문자를 입력받아
시작 태그를 만들고>를 만날 때까지태그 이름 상태가 된다. - 이후 다시
<를 만날 때까지자료 상태가 되어 발행 각각에 맞는 토큰을 발행한다.
트리 구축 알고리즘
<html>
<body>
Hello world
</body>
</html>
-
토큰화에 의해 발행된 각 노드는 생성자에 의해 처리된다.
- 아래의 과정을 거치면 문서 객체가 생성된다.
- html 토큰을 받아 html 이전 모드에서 HTMLHtmlElement 요수를 생성하고 객체 최상단에 추가한다.
- 이후 head 이전 모드가 되는데 위의 예에서는 묵시적으로 생성되어 트리에 추가된다.
- head 다음 모드로 body 안쪽으로 문자열 토큰을 받았으면, 본문 노드가 추가되고 작업이 계속된다.
</body>를 만나면 body 다음 모드가 되어 마지막 파일 토큰을 받으면 파싱을 종료한다.
- DOM 트리에 요소를 추가하는 것이 아니라면, 열린 요소는 스택(임시 버퍼 저장소)에 추가된다.
- 이 스택은 부정확한 중첩과 종료되지 않은 태그를 교정한다.
브라우저의 오류 처리
- Parser는 적어도 아래와 같은 오류를 처리해야 한다.
- 어떤 태그의 안쪽에 추가하려는 태그가 금지된 태그일 때, 일단 허용된 태그를 먼저 닫고 금지된 태그는 외부에 추가한다.
- Parser가 직접 요소를 추가해서는 안 된다.
- 문서 제작자에 의해 뒤늦게 요소가 추가될 수도 있고, 생략 가능한 경우도 있다.
- HTML, HEAD, BODY, TBODY, TR, TD, LI 태그가 이런 경우에 해당한다.
- 문서 제작자에 의해 뒤늦게 요소가 추가될 수도 있고, 생략 가능한 경우도 있다.
- 인라인 요소 안쪽에 블록 요소가 있는 경우, 부모 블록 요소를 만날 때까지 모든 인라인 태그를 닫는다.
- 이런 방법이 도움이 되지 않으면 태그를 추가하거나 무시할 수 있는 상태가 될 때까지 요소를 닫는다.
- 위는 아래의 예제로 이해할 수 있다.
<br>대신</br>- 어떤 사이트는
<br>대신에</br>을 사용한다. - 인터넷 익스플로러, 파이어폭스와의 호환성을 갖기 위해 웹킷은 이것을
<br>로 간주한다.
- 어떤 사이트는
- 어긋난 표
- 표 안에 또 다른 표가 th 또는 td 셀 내부에 있지 않은 것을 어긋난 표라 한다.
- 중첩된 폼 요소
- 폼 안에 또 다른 폼을 넣은 경우 안쪽의 폼은 무시한다.
- 태그 중첩이 너무 깊을 때
- 최대 20개의 중첩만 허용하고 나머지는 무시한다.
- 잘못 닫힌 html 또는 body 태그
- 일부 페이지는 문서가 끝나기 전에 body를 닫아버리기 때문에 브라우저는 body 태그를 닫지 않는다.
- 대신 종료를 위해
end()를 호출한다.
Pattern 클래스
- 정규 표현식이 컴파일된 클래스이다.
- 정규 표현식에 대상 문자열을 검증하거나, 활용하기 위해 사용된다.
- Pattern 클래스는
Pattern.compile()을 통해 생성할 수 있다.
Matcher 클래스
- Pattern 클래스를 받아 대상 문자열과 패턴이 일치하는 부분을 찾는다.
- 또는 전체 일치 여부 등을 판별하기 위해 사용된다.
- Matcher 클래스는 컴파일된 패턴을 사용하기 때문에 만들어진 객체에
matcher()메서드를 사용해 생성할 수 있다. - Matcher에 주어진 input 문자열을 패턴에 맞는지 확인하거나 패턴과 일치하는 문자열을 반복해 추출할 수 있다.
- 이때
find()메서드와group()메서드가 사용된다. (원하는 형태의 값을 찾을 수 있음) find()메서드는 패턴이 일치하는 다음 문자열이 존재한다면 true를 반환하고, 그 위치로 이동한다.- 이를 이용하여 while문을 통해 문자열의 끝까지 조회가 가능하다.
group()메서드는 매칭된 부분을 반환한다.
- 이때

Leave a comment