
[DataBase] CS 스터디 12주차
DB Join이 무엇인지 설명하고, 각각의 종류에 대해 설명해 주세요.
DB Join은 한 데이터베이스 내의 여러 테이블의 레코드를 조합하여 하나의 결과 집합으로 만드는 연산입니다. 관계형 데이터베이스에서는 정규화를 통해 데이터를 여러 테이블로 나누어 저장하므로, 이렇게 분리된 데이터를 효과적으로 검색하기 위해 조인이 필요합니다.
- INNER JOIN
- 가장 흔히 사용되는 조인 방식으로, 두 테이블에서 조건이 일치하는 레코드만을 반환합니다.
- OUTER JOIN
- 조건이 일치하지 않는 레코드도 결과에 포함시킵니다.
- LEFT OUTER JOIN
- 왼쪽 테이블의 모든 레코드와 오른쪽 테이블의 일치하는 레코드를 반환합니다.
- 일치하는 레코드가 없으면 NULL 값으로 채웁니다.
- RIGHT OUTER JOIN
- 오른쪽 테이블의 모든 레코드와 왼쪽 테이블의 일치하는 레코드를 반환합니다.
- FULL OUTER JOIN
- 양쪽 테이블의 모든 레코드를 반환하며, 일치하지 않는 경우 NULL 값으로 채웁니다.
- LEFT OUTER JOIN
- 조건이 일치하지 않는 레코드도 결과에 포함시킵니다.
- CROSS JOIN
- 두 테이블의 모든 가능한 조합을 반환합니다.
- Cartesian product(카테시안 곱)이라고도 합니다.
- NATURAL JOIN
- 두 테이블에서 이름이 같은 모든 컬럼을 기준으로 자동으로 조인을 수행합니다.
- SELF JOIN
- 하나의 테이블을 자기 자신과 조인합니다.
- 주로 계층 구조나 순서 관계를 표현할 때 사용됩니다.
사실, JOIN은 상당한 시간이 걸릴 수 있기에 내부적으로 다양한 구현 방식을 사용하고 있습니다. 그 예시에 대해 설명해 주세요.
Nested Loop Join
가장 기본적인 JOIN 알고리즘으로, 두 테이블을 중첩 반복문처럼 순차적으로 비교합니다.
- 작은 테이블을 driving table로 사용하고, 큰 테이블을 driven table로 사용하는 것이 효율적입니다.
- driving table: JOIN을 할 때 먼저 액세스 되어 ACCESS PATH를 주도하는 테이블, 즉, 조인을 할 때 먼저 액세스 되는 케이블
- driven table: 조인을 할 때 나중에 액세스 되는 테이블
- 내부 테이블의 JOIN 컬럼에 인덱스가 있으면 성능이 크게 향상됩니다.
- 소량의 데이터를 처리할 때 효과적입니다.
Hash Join
대용량 데이터를 처리할 때 주로 사용되는 알고리즘입니다.
- 작은 테이블을 기반으로 해시 테이블을 생성합니다.
- 큰 테이블을 스캔하면서 해시 테이블과 매칭되는 레코드를 찾습니다.
- 대량의 데이터를 처리할 때 Nested Loop Join보다 효율적입니다.
- 해시 테이블 생성에 메모리가 필요하므로, 충분한 메모리가 있을 때 유용합니다.
Sort-Merge Join
두 테이블을 JOIN 키를 기준으로 정렬한 후 병합하는 방식입니다.
- 두 테이블을 JOIN 키로 정렬합니다.
- 정렬된 테이블을 순차적으로 스캔하면서 매칭되는 레코드를 찾습니다.
- JOIN 키에 인덱스가 없는 경우에 유용할 수 있습니다.
- 정렬 작업에 추가적인 I/O가 발생하지만, 대용량 테이블에서 효율적일 수 있습니다.
그렇다면 입력한 쿼리에서 어떤 구현 방식을 사용하는지는 어떻게 알 수 있나요?
Execution Plan이라는 것을 사용해서 알 수 있습니다.
- 말 그대로 SQL 문으로 요청한 데이터를 어떻게 불러올 것인지에 관한 계획, 즉 경로를 의미합니다.
- 대부분의 DBMS에서는 이것을 통해 쿼리의 실행 방식을 확인할 수 있습니다.
- 이것은 데이터베이스가 쿼리를 어떻게 처리할지에 대한 상세한 정보를 제공합니다.
- 어떤 JOIN인지 JOIN 연산자의 종류를 직접 확인할 수 있습니다.
앞 질문들을 통해 인덱스의 중요성을 알 수 있었는데, 그렇다면 JOIN의 성능도 인덱스의 유무의 영향을 받나요?
네, JOIN 연산의 성능은 인덱스의 유무와 설계에 큰 영향을 받습니다. 인덱스는 JOIN 성능을 크게 향상시킬 수 있지만, 적절하게 사용되지 않으면 오히려 성능을 저하시킬 수도 있습니다.
- 예를 들어, JOIN 조건에 사용되는 컬럼에 인덱스가 있으면 JOIN 성능이 크게 향상됩니다.
- 특히 외래 키에 대한 인덱스는 JOIN 성능 향상에 중요합니다.
3중 조인 부터는 동작 방식이 약간 바뀝니다. 어떻게 동작하는지, 그리고 그 방식이 성능에 어떠한 영향을 주는지 설명해 주세요.
동작 방식
- 옵티마이저가 가장 효율적인 조인 순서를 결정합니다.
- 먼저 2개의 테이블을 조인합니다.
- 그 결과를 임시 테이블로 만듭니다.
- 임시 테이블과 3번째 테이블을 다시 조인합니다.
- 4개 이상의 테이블이라면 3-4번 과정을 반복합니다.
성능에 미치는 영향
- 각 단계마다 임시 결과 집합이 생성되어 메모리나 디스크 공간을 사용합니다. 이는 I/O 비용을 증가시킬 수 있습니다.
- 테이블 수가 늘어날수록 최적의 조인 순서를 찾는 것이 더욱 중요해집니다. 잘못된 순서는 성능을 크게 저하시킬 수 있습니다.
- 여러 단계의 조인으로 인해 Execution Plan이 복잡해져 최적화가 어려워질 수 있습니다.
B-Tree와 B+Tree에 대해 설명해 주세요.
B-Tree와 B+Tree는 모두 자가 균형 트리 구조로, 데이터를 정렬된 상태로 유지합니다.
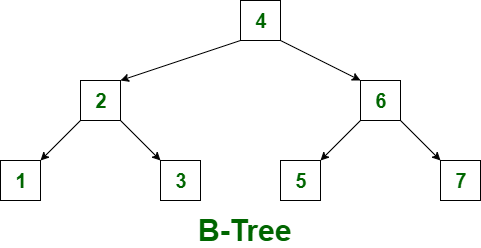
- B-Tree
- 모든 노드(내부 노드와 리프 노드)에 키와 데이터를 저장합니다.
- 각 노드는 여러 개의 키를 가질 수 있어 트리의 높이를 낮출 수 있습니다.
- 검색, 삽입, 삭제 연산의 시간 복잡도는 $O(log N)$입니다.
- 범위 검색 시 트리를 여러 번 순회해야 할 수 있습니다.
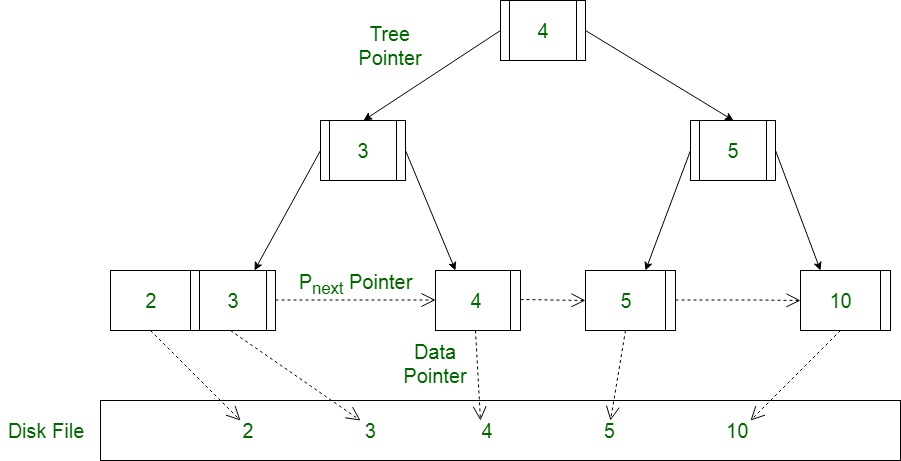
- B+Tree
- 내부 노드에는 키만 저장하고, 모든 데이터는 리프 노드에 저장합니다.
- 리프 노드들은 연결 리스트로 연결되어 있어 순차 접근이 용이합니다.
- 검색 연산의 시간 복잡도는 B-Tree와 동일한 $O(log N)$입니다.
- 범위 검색에 특히 효율적입니다.
- 차이점
- B-Tree는 모든 노드에, B+Tree는 리프 노드에만 저장합니다.
- B+Tree의 리프 노드는 연결 리스트로 연결되어 있어 순차 접근이 빠릅니다.
- B+Tree가 B-Tree보다 범위 검색에 더 효율적입니다.
- B+Tree는 내부 노드에 데이터를 저장하지 않아 더 많은 키를 저장할 수 있어 트리의 높이가 더 낮아질 수 있습니다.
대부분의 현대 데이터베이스 시스템은 범위 검색과 순차 접근에 더 효율적인 B+Tree를 사용합니다. MySQL의 InnoDB 스토리지 엔진도 B+Tree를 사용하고 있습니다.
그렇다면, B+Tree가 B-Tree에 비해 반드시 좋다고 할 수 있을까요? 그렇지 않다면 어떤 단점이 있을까요?
B+Tree가 B-Tree에 비해 많은 장점이 있지만, 모든 상황에서 반드시 더 좋다고 할 수는 없습니다.
B+Tree의 단점
- 공간 사용량 증가
- B+Tree는 모든 키를 리프 노드에 중복 저장하므로, 동일한 데이터에 대해 B-Tree보다 더 많은 저장 공간을 사용할 수 있습니다.
- 단일 레코드 검색 시 성능
- 특정 키를 검색할 때 B+Tree는 항상 리프 노드까지 탐색해야 합니다. 반면 B-Tree는 중간 노드에서 데이터를 찾을 수 있어 일부 경우에 더 빠를 수 있습니다.
- 구현 복잡성
- B+Tree는 리프 노드 간의 연결 리스트 유지와 같은 추가적인 구조로 인해 B-Tree보다 구현이 더 복잡할 수 있습니다.
- 삽입/삭제 연산의 오버헤드
- B+Tree에서 데이터 삽입이나 삭제 시, 리프 노드와 내부 노드 모두를 업데이트해야 하므로 B-Tree에 비해 더 많은 작업이 필요할 수 있습니다.
B-Tree가 더 적합할 수 있는 상황
- 빈번한 업데이트
- 데이터의 삽입과 삭제가 매우 빈번한 경우, B-Tree가 더 효율적일 수 있습니다.
- B-Tree는 내부 노드에도 데이터를 저장하므로 노드 분할이나 병합이 덜 발생할 수 있습니다.
- 메모리 제약
- 저장 공간이 제한적인 환경에서는 B-Tree가 더 적합할 수 있습니다.
- B+Tree는 모든 키를 리프 노드에 중복 저장하므로 더 많은 공간을 사용합니다.
- 단일 레코드 조회
- 범위 검색보다 특정 키의 빠른 조회가 주로 필요한 경우, B-Tree가 더 효율적일 수 있습니다.
DB에서 RBT를 사용하지 않고, B-Tree/B+Tree를 사용하는 이유가 있을까요?
디스크 접근 최적화
- B-Tree와 B+Tree는 디스크의 블록 단위 접근에 최적화되어 있습니다.
- 각 노드가 디스크 블록 크기에 맞게 설계되어 I/O 작업을 최소화합니다.
- B-Tree와 B+Tree는 RBT보다 트리의 높이가 낮습니다. 이는 디스크 접근 횟수를 줄여 검색 성능을 향상시킵니다.
대용량 데이터 처리
- B-Tree와 B+Tree는 대용량 데이터를 효율적으로 처리할 수 있도록 설계되었습니다.
- 각 노드가 많은 키를 저장할 수 있어 대규모 데이터베이스에 적합합니다.
- 특히 B+Tree는 리프 노드들이 연결 리스트로 연결되어 있어 범위 검색에 매우 효율적입니다.
즉, RBT가 메모리 내 작업에는 효율적일 수 있지만, 디스크 기반 저장소의 특성을 고려한 B-Tree와 B+Tree가 더 적합합니다.
오름차순으로 정렬된 인덱스가 있다고 할 때, 내림차순 정렬을 시도할 경우 성능이 어떻게 될까요? B-Tree/B+Tree의 구조를 기반으로 설명해 주세요.
- **탐색 효율성**
- B-Tree와 B+Tree는 기본적으로 오름차순으로 정렬되어 있기 때문에, 내림차순 정렬을 위해서는 트리를 역순으로 탐색해야 합니다.
- 이는 추가적인 연산을 필요로 하지만, 트리의 구조 자체는 변경되지 않으므로 탐색의 시간 복잡도는 여전히 $O(log N)$을 유지합니다.
- **순차 접근 성능**
- B+Tree의 경우, 리프 노드들이 연결 리스트로 연결되어 있어 순차 접근이 매우 효율적입니다.
- 내림차순 정렬을 위해서는 이 연결 리스트를 역방향으로 탐색해야 하지만, 여전히 효율적인 순차 접근이 가능합니다.
- **범위 쿼리 성능**
- 범위 쿼리의 경우, 내림차순 정렬을 위해 트리의 끝에서부터 시작하여 역방향으로 진행해야 합니다.
- 이는 약간의 추가 오버헤드를 발생시킬 수 있지만, B+Tree의 연결된 리프 노드 구조 덕분에 여전히 효율적으로 수행될 수 있습니다.
- **캐시 효율성**
- 데이터베이스 시스템은 일반적으로 순방향 읽기에 최적화되어 있습니다
- 내림차순 정렬은 역방향 읽기를 필요로 하므로, 캐시 효율성이 다소 떨어질 수 있습니다.
결론적으로, 약간의 성능 저하가 있을 수 있지만 전반적인 시간 복잡도는 유지됩니다. 대규모 데이터셋에서 자주 내림차순 정렬이 필요한 경우, 별도의 내림차순 인덱스를 생성하는 것이 성능 향상에 도움이 될 수 있습니다.
※ 하지만 상대적으로 차이가 있음 이 포스트 정독
Leave a comment