
[Database] CS 스터디 3주차
깃허브 인터뷰 레포지토리에 있는 질문들을 가지고 매주 토론하는 스터디를 진행 중입니다.
클러스터링 / 레플리케이션
RDBMS, NoSQL에서의 클러스터링/레플리케이션 방식에 대해 설명해 주세요.
레플리케이션 (Replication)
- 레플리케이션
- 여러 개의 데이터베이스를 권한에 따라 수직적인 구조(Master-Slave)로 구축하는 방식
- 스토리지 여러개
- 마스터 노드는 쓰기 작업만 처리하고, 슬레이브 노드는 읽기 작업만 처리함
- 비동기 방식으로 노드들 간의 데이터를 동기화함
- 마스터와 슬레이브 간의 데이터 무결성 검사를 하지 않음
- 동작 방식
- 마스터 노드에 쓰기 트랜잭션이 수행됨
- 마스터 노드는 데이터를 저장하고 트랜잭션에 대한 로그를 Binary Log에 기록
- 슬레이브 노드의 I.O 스레드는 마스터 노드의 Binary Log를 Relay Log에 복사
- 슬레이브 노드의 SQL 스레드는 Relay Log를 한 줄씩 읽어 데이터를 저장함
- Binary Log
- DB 변경 내용을 기록하는 데 이용하는 로그
- Replay Log
- 슬레이브 DB에만 위치
- 마스터 DB의 Binary Log를 복사하여 저장하는 데 이용하는 로그
- Binary Log
- 장점
- DB 요청의 60~80%가 읽기 작업(슬레이브 노드)이기 때문에 레플리케이션만으로도 성능을 높일 수 있음
- 비동기 방식이기 때문에 지연 시간이 거의 없음
- 비동기, 동기, 반동기 모두 지원 (mysql 버전 높을 때)
- 반동기
- 복제 슬레이브 서버가 여러개가 있으면 최소한 하나에는 Relay 로그에 넣어야지 마스터 DB의 서버에서 커밋함
- MHA 방식
- 마스터 DB가 오류가 나더라도 슬레이브 서버의 하나는 가지고 있는 거라 로그를 읽어서 DB 복구 가능
- 반동기
- 비동기, 동기, 반동기 모두 지원 (mysql 버전 높을 때)
- 단점
- 노드들 간의 데이터 동기화가 보장되지 않아 데이터 일관성을 보장하지 못할 수 있음
- 마스터 노드가 다운되면 복구 및 대처가 까다로움
클러스터링 (Clustering)
- 클러스터링
- 여러 개의 데이터베이스를 수평적인 구조로 구축하는 방식
- 분산 환경을 구성하여,
Single Point Of Failure과 같은 문제를 해결할 수 있는 Fall Over 시스템을 구축하는 것을 목적으로 함 - 동기 방식으로 노드들 간의 데이터를 동기화함
- 스토리지 하나로 관리
- 동작 방식
- 1개의 노드에 쓰기 트랜잭션이 수행되고, 커밋을 실행
- 실제 디스크에 내용을 쓰기 전에, 다른 노드로 데이터 복제를 요청
- 다른 노드에서 복제 요청을 수락했다는 신호를 보내고, 디스크에 쓰기 시작
- 다른 노드로부터 신호를 받으면, 실제 디스크에 데이터 저장
- 장점
- 노드들 간에 데이터를 동기화하여 항상 일관성 있는 데이터를 얻을 수 있음
- 노드가 죽어도 다른 노드가 살아 있어, 시스템 장애가 발생하지 않음
- 단점
- 여러 노드 간 데이터를 동기화하는 시간이 필요하여 레플리케이션보다 쓰기 성능이 떨어짐
- 장애가 전파되면 처리가 까다롭고, 데이터 동기화에 의해 스케일링에 한계가 존재함
- 종류
- Active-Active는 클러스터를 항상 기동하여 가용 가능한 상태로 둠
- Active-Standby는 일부 클러스터는 가동하고, 일부 클러스터는 대기 상태로 구성
- RDBMS의 적용
- 레플리케이션으로 구축하면 Master-Slave 구조로 구성하여 마스터는 DML(쓰기)만 처리하고, 슬레이브는 읽기만 수행함
- 사용자 증대 등으로 인해 부하가 증가하면, 슬레이브를 증설
- 슬레이브를 증설하면, 부하 분산으로 인해 로드 밸런서를 구축해야 함
- 클러스터링으로 구축하면 Mangement Node, Data Node, SQL Node로 구성함
- 권장: Management Node 2대, Data Node 2대, SQL Node 2대
- 공유 디스크나 락에 대한 성능 저하는 발생하지 않음
- Data Node를 초기에 구축하면, 데이터 증가로 인한 노드 추가 시 시스템 전체 정지 후에 재구축해야 한다는 단점이 존재함
- 레플리케이션으로 구축하면 Master-Slave 구조로 구성하여 마스터는 DML(쓰기)만 처리하고, 슬레이브는 읽기만 수행함
- NoSQL의 적용
- 레플리케이션으로 구축하면 RDBMS의 적용과 같음
- (MongoDB) 클러스터링으로 구축하면, 많은 데이터를 여러 노드에 분산 저장하는 방식으로 3종류 서버로 구성함
- Mongod, Mongod configsvr, mongs
- 장점
- 수평적 확장성
- 읽기/쓰기 연산 성능 향상
이러한 분산 환경에선, 트랜잭션을 어떻게 관리할 수 있을까요?
- 대표적인 분산 트랜잭션 관리 방안으로는 2Phase Commit과 Saga Pattern이 존재함
2Phase Commit (2PC) 알고리즘
- 2PC 알고리즘은 분산 시스템에서 트랜잭션을 변경할 수 있는 기능을 제공하는데, 제한 사항이 존재함
- 2PC의 두 phase는 투표 단계와 커밋 단계가 있음
- 투표 단계에서는 Coordinator가 트랜잭션의 일부가 될 모든 대상 서비스에 직접 연결하여 상태 변경이 가능한지 확인 요청함
- 투표 단계
- Coordinator는 고객 서비스의 CUSTID 0001 삭제 요청과 이체서비스의 UserID 0001 삭제 요청을 보냄
- 고객서비스와 이체서비스에서 상태 변경 가능여부에 대해 투표하고 해당 row에 락을 걺
- 투표 결과 모두 가능하다면 각 서비스에서 상태를 변경하고 커밋 단계로 이동함
- 하나라도 상태 변경이 불가능하다고 투표하면 트랜잭션은 중단되고 롤백을 진행함
- 투표가 됐다고 변경사항이 즉시 적용되지는 않음
- 투표에 동의한 서비스의 변경이 나중에 이루어질 수 있도록 반영 결과에 대해 락을 걸어 둠
- 투표가 됐다고 변경사항이 즉시 적용되지는 않음
- 커밋 단계
- Coordinator는 커밋 메시지를 각 서비스로 전달
- 고객서비스는 CUSTID 0001의 row를 삭제하고, 이체서비스는 UserID 0001의 row를 삭제
- 커밋단계에서 모든 서비스에 정확히 동시에 변경이 적용된다고 보장할 수는 없음
- Coordinator가 각 서비스에 커밋 요청을 보내야 하는데, 이 메시지가 다른 시간에 도착할 수도 있음
- 타이밍 이슈로 인해 고객서비스에 대한 변경사항은 볼 수 있지만, 이체서비스에 대한 변경 사항은 아직 반영되지 않았을 수도 있음
- 커밋단계에서 모든 서비스에 정확히 동시에 변경이 적용된다고 보장할 수는 없음
- 결론
- 2PC는 서비스가 증가할수록 시스템의 대기시간이 길어지고, 이는 응답시간의 증가를 초래함
- 특히 락을 걸어야 하는 row의 범위가 넓거나 트랜잭션 기간이 길면 시스템에 엄청난 대기 시간을 발생시키기 때문에, 2PC는 일반적으로 수명이 짧은 작업에만 사용하는 것을 권장함
- 2PC는 서비스가 증가할수록 시스템의 대기시간이 길어지고, 이는 응답시간의 증가를 초래함
Saga Pattern
- Saga는 단일 데이터베이스에서 장시간 동작하는 트랜잭션을 지원하는 메커니즘으로 계획됐지만, 여러 서비스에 걸친 트랜잭션 관리에도 적합함
- NoSQL 같이 분산 트랜잭션 처리를 지원하지 않는 경우에도 Saga Pattern을 이용하여 데이터 일관성을 보장받을 수 있음
- Saga 패턴은 각 서비스의 로컬 트랜잭션을 순차적으로 처리하여, 각 로컬 트랜잭션이 데이터베이스를 업데이트시킨 다음, Saga 내의 next 로컬 트랜잭션을 trigger하는 메시지 또는 이벤트를 게시함
- 트랜잭션이 실패하여 롤백이 필요한 경우, 이전 로컬 트랜잭션이 작성한 변경 사항을 취소하는 일련의 보상 트랜잭션을 통해 전체의 일관성을 유지함
Orchestration 방식
- Orchestrator를 중심으로 하는 Invoke/Reply 방식으로, 트랜잭션이 실패하면 Orchestrator가 그동안의 호출에 대한 보상 이벤트를 호출하여 데이터 정합성을 보장함
- 메인이 되는 서비스의 Saga 모듈이 존재함
- 트랜잭션에 참가하는 개별 마이크로 서비스들의 로컬 트랜잭션은 Saga Orchestrator에 의해 호출되고, 상태값 설정으로 설정됨
- 참가하는 트랜잭션이 모두 처리되면 메인 서비스의 상태가 변경됨
- 트랜잭션에 참가하는 특정 마이크로 서비스에서 로컬 트랜잭션 오류가 발생하면 Saga Orchestrator는 롤백 서비스를 호출함
- 장점
- 서비스의 복잡도가 감소
- 단점
- Orchestrator 추가에 따른 인프라 복잡도 증가와 중간에서의 통제를 위한 복집한 로직이 됨
Choreography 방식
- 중간에 Kafka와 같은 메시지 큐를 통해 비동기 방식으로 전달
- 각 서비스간 이벤트를 주고 받는 Event Pub/Sub 방식
- 만약 트랜잭션이 실패하면 취소된 애플리케이션에서 보상 이벤트를 발행해서 롤백을 시도
- 메인이 되는 서비스에서 관련 서비스의 로컬 트랜잭션을 호출
- 각 서비스간 이벤트를 주고 받는 Event Pub/Sub 방식
- 특정 서비스에서 로컬 트랜잭션 오류가 발생하면, 해당 서비스에서 자신을 호출한 서비스의 롤백 서비스를 호출함
- 장점
- 구축하기 쉬움
- 단점
- 각 서비스가 이벤트를 listen하고 있어야 함
- 개별 트랜잭션들이 공통된 공유 ID를 정의해야 함
- 이벤트를 추적해야 함
- 새로운 스텝 추가 시 복잡도가 증가함
마스터, 슬레이브 데이터 동기화 전 까지의 데이터 정합성을 지키는 방법은 무엇이 있을까요?
- 완벽하게 동기화를 구현하기는 어렵기 때문에, 실시간성을 보장해야 하는 쿼리는 마스터로 처리함
다중 트랜잭션 상황에서의 Deadlock 상황과, 이를 해결하기 위한 방법에 대해 설명해 주세요.
- 락들의 경합이 발생하면 Blocking이고, 이 때 특정 세션이 작업을 진행하지 못하고 멈추게 됨
- 공유락-베타락, 베타락-베타락 관계에서 블로킹이 발생할 수 있는데, 이를 해결하려면 Transaction commit 또는 rollback이 필요함
- 교착 상태(Deadlock)은 두개 이상의 트랜잭션이 특정 자원의 락을 획득한 채 다른 트랜잭션이 소유하고 있는 락을 요구한다면, 아무리 기다려도 상황이 바뀌지 않는 상태를 말함 (공통된 자원이 있는데 서로가 무한정 대기 상태에 빠지는 거)
- Oracle은 데드락을 감지하면 한쪽 트랜잭션을 풀어버림
- 데이터베이스에서 교착상태를 해결하기 위한 방법은 예방 기법, 회피 기법, 낙관적 병행 제어 기법, 빈도 줄이기 기법이 있음
데드락 예방 기법
- 각 트랜잭션이 실행되기 전에 필요한 모든 자원을 락함 (병행성은 떨어짐)
- SET LOCK_TIMEOUT 문을 통해 일정 시간이 지나면 쿼리를 취소함
데드락 회피 기법
- 회피 기법은 자원을 할당할 때 타임스탬프를 활용하여 교착상태가 일어나지 않도록 회피하는 방법임
- Wait-Die 방식 (
- 트랜잭션 A가 트랜잭션 B에 의해 락된 데이터를 요청할 때, 트랜잭션 A가 먼저 들어온 트랜잭션이라면 대기함
- 트랜잭션 A가 나중에 들어온 트랜잭션이라면 포기(Die)하고 나중에 다시 요청함
- Wound-Wait 방식
- 트랜잭션 A가 트랜잭션 B보다 먼저 들어온 트랜잭션이면 데이터를 선점(Wound)함
- 트랜잭션 A가 트랜잭션 B보다 나중에 들어온 트랜잭션이라면 대기(Wait)함
낙관적 병행 제어 기법
- 트랜잭션이 실행되는 동안에는 검사를 수행하지 않고, 트랜잭션이 커밋된 후에 데이터에 문제가 있다면 롤백함
- 판독 > 확인 > 기록의 단계를 따르고, 확인 단계를 성공적으로 거친 트랜잭션만 기록 단계를 수행할 수 있음
빈도 줄이기
- 트랜잭션을 자주 커밋
- 정해진 순서로 테이블에 접근
- 읽기 락 획득(SELECT ~ FOR UPDATE)의 사용을 피함
- 테이블 단위의 락을 통해 갱신을 직렬화
- 인덱스 설계
- UPDATE 시에 인덱스를 타지 않으면 테이블 전체에 락이 걸릴 수 있음
- 고립수준을 낮춤
샤딩 방식은 무엇인가요? 만약 본인이 DB를 분산해서 관리해야 한다면, 레플리케이션 방식과 샤딩 방식 중 어떤 것을 사용할 것 같나요?
샤딩
- 데이터베이스 트래픽을 분산할 수 있는 중요한 수단으로, 각 DB 서버에서 데이터를 분할해 저장하는 방식임
- 수평 분할 (수평 파티셔닝의 일종 = 샤딩)
- 샤딩은 분할하여 다른 데이터베이스에
- 파티셔닝은 같은 데이터베이스에
- 레플리케이션도 데이터베이스 트래픽을 분산할 수 있으니까 “각 DB 서버에서 데이터를 분할해 저장하는 방식”이 중요함
- 해당 데이터에 접근할 때는 샤딩키를 사용하여 동적으로 DB서버를 매핑하는 과정이 필요함
- 수평 분할 (수평 파티셔닝의 일종 = 샤딩)
- 샤딩을 이용하면 특정 DB의 장애가 전면 장애로 이어지는 것을 방지할 수 있음
- 조건
- 라우팅을 위해 구분할 수 있는 유일한 키값이 필요함
- 설정으로 쉽게 증설이 가능해야 함
Key-Base Sharding
- Modular
- Hash-Base
모듈러 샤딩 (Modular Sharding)
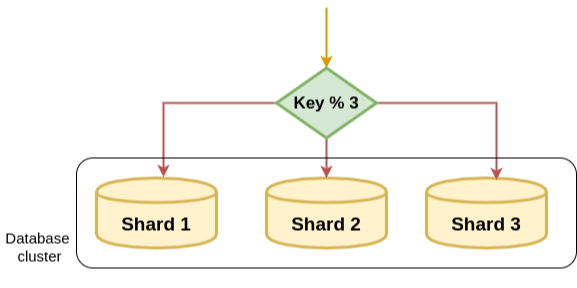
- PK를 모듈러 연산한 결과로, DB를 라우팅하는 방식
- 장점
- 레인지 샤딩에 비해 데이터가 균일하게 분산됨
- 트래픽을 안정적으로 소화
- 데이터베이스 리소스를 최대 활용
- 레인지 샤딩에 비해 데이터가 균일하게 분산됨
- 단점
- 데이터베이스를 추가 증설하는 과정에서 이미 적재된 데이터의 재정렬이 필요함
- 데이터량이 일정 수준에서 유지될 것으로 예상되는 곳에 적용해야 함
레인지 샤딩 (Range Sharding)
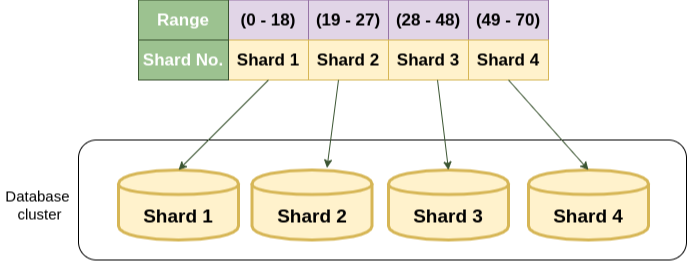
- PK 범위를 기준으로 데이터베이스를 특정함
- 장점
- 모듈러 샤딩에 비해 증설에 재정렬 비용이 들지 않음
- 단점
- 일부 데이터베이스에 데이터가 몰릴 수 있음
- 데이터가 급격히 증가할 여지가 있다면 적절한 방식임
- 하지만 트래픽 분산이 균등하지 않을 수 있기 때문에 트래픽이 몰리는 데이터베이스는 분산시키고, 트래픽이 저조한 데이터베이스는 통합시키는 과정이 필요함
디렉토리 샤딩 (Directory-Based Sharding)
- 별도의 조회 테이블을 사용하여 샤딩을 수행함
- 특정 데이터를 찾을 수 있는 정적인 정보를 갖는 테이블에 따라서 데이터가 저장될 샤드가 지정됨
- PK의 범위에 따라 샤드가 정해지는 레인지 샤딩과는 다르게, 각 키들이 자신의 샤드에 들어가게 됨
- 장점
- 유연함
- 동적으로 샤드를 추가하는 것도 비교적 쉬움
- 단점
- 연산 전에 조회 테이블에 연결해야 해서 애플리케이션 성능이 좋지 못할 수 있음
샤딩이 필요할 때
- 애플리케이션 데이터의 양이 단일 데이터베이스 노드의 스토리지 한계를 초과할 때
- 쓰기/읽기 양이 단일 노드가 핸들링할 수 있는 수준을 넘어설 때
- 하나의 데이터베이스 노드에 가능한 네트워크 대역폭을 초과할 때
샤딩할 때 유의할 점
- 샤딩의 필요성을 예측하고 실제 사용량이 샤딩이 필요한 정도로 커지기 전에 샤딩하기
- 샤딩 키를 신중하게 선택하기
샤딩을 대체해 보기
- 모든 컴포넌트들이 하나의 서버에 있는 애플리케이션이면 원격 데이터베이스를 사용할 수 있음
- 읽기 퍼포먼스가 문제라면 캐싱을 활용하기
- 마스터-슬레이브 구조를 활용하기
- scale up이 샤딩에 비해 공수가 적음
정규화
정규화가 무엇인가요?
- 정규화
- 이상현상(Anomaly)이 있는 릴레이션을 분해해 이상현상을 없애는 과정으로, 이상현상이 존재하는 릴레이션을 분해해서 여러 개의 릴레이션을 생성한다. 정규형이 높아질 수록 이상현상은 줄어들게 된다.
장점
이상현상을 제거할 수 있다 정규화된 데이터베이스 구조에서 새로운 데이터 형의 추가로 인한 확장 시, 그 구조를 변경하지 않거나 일부만 변경해도 된다 데이터베이스와 연동된 응용 프로그램에 최소한의 영향만 미친다
단점
테이블의 분해로 인해 테이블 간 JOIN 연산이 많아진다: 반정규화(De-normalization)이 필요할 수 있음 질의에 대한 응답 시간이 느려질 수 있다 (근데 빨라질 수도?) 정규화의 3가지 원칙 정보의 무손실: 분해된 릴레이션이 표현하는 정보는 분해 전 정보를 모두 포함해야 한다. 최소 데이터 중복: 이상현상을 제거하고, 데이터 중복을 최소화해야 한다 분리의 원칙: 하나의 독립된 관계성은 하나의 독립된 릴레이션으로 분리해서 표현해야 한다 함수 종속성 (Functional Dependency) 함수 종속성: 어떤 속성 A의 값을 알면 다른 속성 B의 값이 유일하게 정해지는 관계를 말한다
A->B로 표기하면 A를 B의 결정자(Determinant)라 부르고, B는 A에 종속한다(Dependent)라고 한다
제 1정규형 (1NF)
각 컬럼이 하나의 속성만을 가져야 한다 하나의 컬럼은 같은 종류의 값을 가져야 한다 각 컬럼이 유일한 이름을 가져야 한다 컬럼의 순서가 상관 없어야 한다
제 2정규형 (2NF)
제 1정규형의 조건을 만족해야 한다 모든 컬럼이 부분적 종속(Partial Dependency)이 없어야 한다. 즉, 모든 컬럼이 완전 함수 종속을 만족해야 한다 부분적 종속: 기본키 중에 특정 컬럼에만 종속됨을 의미한다. 완전 함수 종속: 기본키의 부분집합이 결정자가 되어서는 안됨을 의미한다
제 3정규형 (3NF)
제 2정규형의 조건을 만족해야 한다 기본키를 제외한 속성들 간의 이행 종속성 (Transitive Dependency)이 없어야 한다 이행 종속성: A->B, B->C일 때 A->C가 성립한다. A를 알면 B를 알고, 이를 통해 C를 알 수 있다.
BCNF (Boyce-Codd Normal Form)
제 3정규형을 만족해야 한다 모든 결정자가 후보키 집합에 속해야 한다. 즉, 후보키 집합에 없는 컬럼이 결정자가 되어서는 안된다.
정규화를 하지 않을 경우, 발생할 수 있는 이상현상에 대해 설명해 주세요.
삽입 이상 (Insertion Anomaly)
튜플 삽입 시 특정 속성에 해당하는 값이 없어 NULL을 입력해야 하는 현상
삭제 이상 (Deletion Anomaly)
튜플 삭제 시 같이 저장된 다른 정보까지 연쇄적으로 삭제되는 현상
갱신 이상 (Update Anomaly)
튜플 갱신 시 중복된 데이터의 일부만 갱신되어 일어나는 데이터 불일치 현상
각 정규화에 대해, 그 정규화가 진행되기 전/후의 테이블의 변화에 대해 설명해 주세요.
정규화가 무조건 좋은가요? 그렇지 않다면, 어떤 상황에서 역정규화를 하는게 좋은지 설명해 주세요.
역정규화 (De-normalization)
시스템의 성능 향상을 위해 정규화된 데이터 모델을 통합하는 작업으로, 데이터 통합/분할/추가, 중복 속성 추가 등으로 구현할 수 있다.
역정규화를 수행하면 테이블이 단순해져서 관리 효율성이 증가하지만, 데이터의 일관성/무결성은 보장되지 않을 수 있다.
역정규화가 필요할 때
수행 속도가 현저히 느릴 때 테이블의 조인연산이 지나치게 많이 필요해서 데이터를 조회하는 것이 어려울 때 테이블에 많은 데이터가 있고, 다량의 범위 혹은 특정 범위를 자추 처리해야 하는 경우
View
View가 무엇이고, 언제 사용할 수 있나요?
- 가상의 테이블로, 일반 테이블로 사용하지만 사용자에게 보여줄 수 있는 정보만 따로 보여줄 수 있고, 보여주고 싶지 않는 정보는
WITH ENCRYPTION을 사용하여 암호화할 수 있음 - 기본 테이블로부터 유도된 가상/임시 테이블로, 저장장치 내에 물리적으로 존재하지 않음
- 뷰를 사용해서 JOIN문을 최소화하여 사용상의 편의성을 향상시킬 수 있음
ENCRYPTION은 View뿐만이 아니라 다른 곳에서도 사용할 수 있는 SQL 문법임- 한번 저장해 두면 재활용할 수 있음
특징
- 뷰는 테이블에서 유도된 임시 테이블이라서 기본 테이블과 같은 형태의 구조를 사용함
- 뷰는 가상 테이블이라서 물리적으로 구현돼있지 않음
- 데이터의 논리적 독립성을 제공할 수 있음
- 필요한 데이터만 뷰로 정의해서 처리할 수 있어서 관리와 쿼리가 쉬워짐
- 뷰를 통해서만 데이터에 접근하면 뷰에 나타나지 않은 데이터를 안전히 보호할 수 있음
- 기본 테이블의 기본키를 포함한 속성 집합으로 뷰를 구성해야지만 삽입/삭제/갱신/연산이 가능함
- 일단 정의된 뷰는 다른 뷰의 정의의 기초가 될 수 있음
- 뷰가 정의된 기본 테이블/뷰를 삭제하면 그 뷰도 자동으로 삭제됨
- 항상 최신 데이터를 가지고 있음
장점
- 논리적 데이터 독립성을 제공함
- 동일 데이터에 대해 동시에 여러 사용자의 상이한 요구를 지원함
- 사용자의 데이터관리가 쉬워짐
- 접근 제어를 통한 보안을 제공함
단점
- 독립적인 인덱스를 가질 수 없음
- 뷰의의 정의는 변경할 수 없음
- 변경이 필요하면 삭제 후 재생성해야 함
- 뷰로 구성된 내용에 대한 연산에 제약이 따름
그렇다면, View의 값을 수정해도 실제 테이블에는 반영되지 않나요?
- 결국 가상 테이블이기 때문에 반영되지 않음
- 하지만 이와 같은 조건에 한에서만 반영됨
DB Join
DB Join이 무엇인지 설명하고, 각각의 종류에 대해 설명해 주세요.
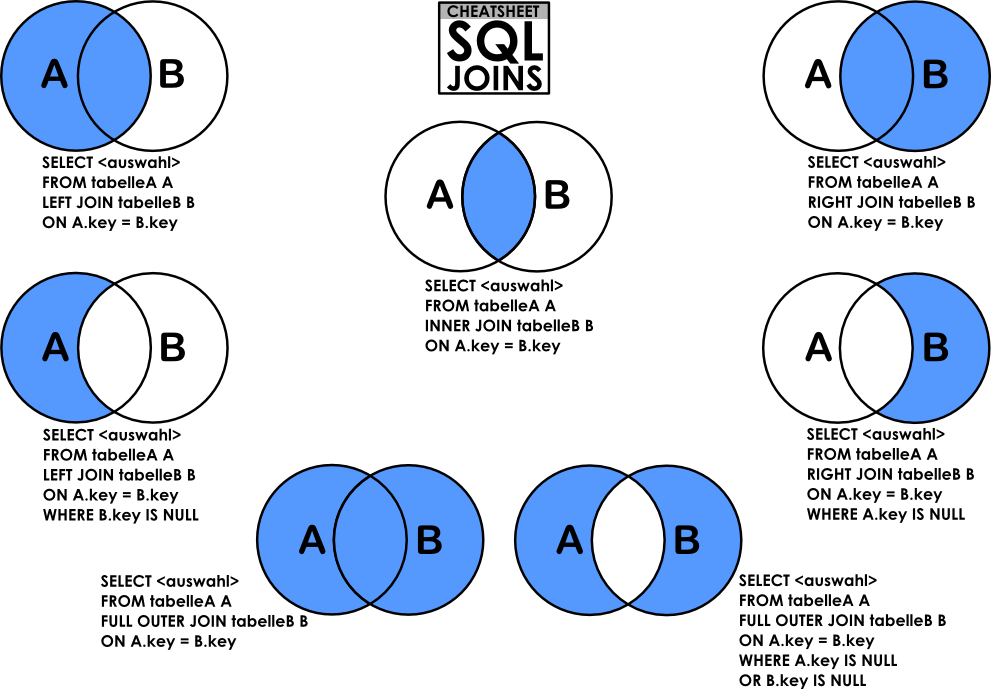
Inner Join (내부 조인, 교집합)
- 공통 부분만 SELECT
SELECT A.ID, A.ENAME, A.KNAME
FROM A INNER JOIN B
ON A.ID = B.ID;
Left/Right Join (부분 집합)
- Join 기준 왼쪽(오른쪽)에 있는 것 전부 SELECT
- 공통적인 부분 + Left에 있는 것만
SELECT A.ID, A.ENAME, A.KNAME
FROM A LEFT OUTER JOIN B
ON A.ID = B.ID;
- Join 기준 왼쪽(오른쪽)에 있는 것만 SELECT
- A - B
SELECT A.ID, A.ENAME, A.KNAME
FROM A LEFT OUTER JOIN B
ON A.ID = B.ID
WHERE B.ID IS NULL;
Outer Join (외부 조인, 합집합)
- A와 B가 가지고 있는 데이터 모두 SELECT
- Oracle은 outer join을 지원하지만, MySQL은 지원하지 않기 때문에 Left 조인 + Right 조인을 합쳐서 사용해야 함
SELECT A.ID, A.ENAME, A.KNAME
FROM A FULL OUTER JOIN B
ON A.ID = B.ID
- 오른쪽에만 있는 것과 왼쪽에만 있는 것 SELECT
SELECT A.ID, A.ENAME, A.KNAME
FROM A FULL OUTER JOIN B
ON A.ID = B.ID
WHERE A.ID IS NULL OR B.ID IS NULL
Cross Join (상호 조인)
- 한 쪽 테이블의 모든 행과 다른 쪽 테이블의 모든 행을 조인시키는 기능
- 조인 결과의 전체 행 수는 두 테이블의 각 행의 개수를 곱한 수
- ON구문을 사용할 수 없으며, 주로 의미없는 대용량 데이터를 생성하고자 할 때 사용함
SELECT * FROM buy CROSS JOIN member;
Self Join (자체 조인)
- 자신이 자신과 조인해서 1개의 테이블을 사용
- 테이블의 서로 다른 별칭을 사용해 서로 다른 것처럼 사용하면 됨
사실, JOIN은 상당한 시간이 걸릴 수 있기에 내부적으로 다양한 구현 방식을 사용하고 있습니다. 그 예시에 대해 설명해 주세요.
SQL에서 조인 연산을 수행할 때 내부적으로 선택되는 알고리즘에는 Nested Loops Join, Hash Join, Sort Merge Join 등이 있다. 이 중 어느 알고리즘을 선택할지는 데이터의 크기, 결합키(Key), 인덱스(Index)에 따라 옵티마이저가 결정한다.
옵티마이저 (Optimizer): SQL쿼리를 실행했을 때 옵티마이저는 그 쿼리를 전달받아 위의 조건을 고려해 실행계획을 작성하고, 각 선택지의 비용을 연산하여 가장 낮은 비용을 가진 실행계획을 선택한다.
Nested Loops Join
- Nested Loops Join
- 중첩 반복을 사용하는 알고리즘
- 테이블 A와 테이블 B가 어떤 Key를 기준으로 결합을 진행한다
- 테이블 A (Driving Table)의 첫번째 행부터 출발해 테이블 B (Driven Table)의 모든 행을 스캔해서 결합 조건이 맞으면 값을 리턴한다
- 테이블 A의 첫 행의 스캔이 끝나면 두번째 행이 테이블 B의 모든 행을 스캔한다
- 2~3번의 과정을 반복해서 테이블 A의 마지막 행이 테이블 B의 모든 행을 스캔하면 결합이 완료된다. 각 테이블의 결합 대상 레코드 수를 R(A), R(B)라 하면 접근되는 레코드 수는 R(A)R(B)다. 성능을 높이려면 R(A)R(B)의 값을 낮춰야 하는데, 이를 위해서는 Driving Table이 작고, Driven Table의 결합키 필드에 인덱스가 존재해야 한다. Driven Table의 결합키에 인덱스가 존재하면 Driving Table에서 Driven Table을 스캔할 때 모든 행에 대해 스캔할 필요가 없어진다. 어느 테이블을 Driving Table로 선정할지도 옵티마이저의 몫이다. Inner Join에는 실행비용을 최소화하는 방향으로 지정하지만, Outer Join은 어느 테이블을 먼저 읽는지에 따라 결과값이 달라지기 때문에 옵티마이저가 선정하지 않고, 쿼리의 입력을 따른다.
Sort Merge Join (정렬 병합 조인)
- Sort Merge Join
- 조인 컬럼을 기준으로 데이터를 정렬하여 조인 수행
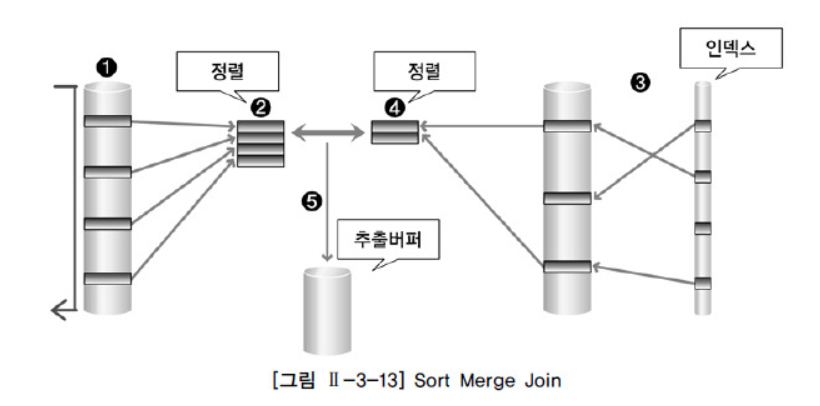
- Driving Table에서 주어진 조건을 만족하는 행을 찾는다
- Driving Table의 조인 키를 기준으로 정렬 작업을 수행한다
- 1~2번의 작업을 Driving Table의 조건을 만족하는 모든 행에 대해 반복 수행한다
- Driven Table에서 주어진 조건을 만족하는 행을 찾는다
- Driven Table의 조인 키를 기준으로 정렬 작업을 수행한다
- 4~5번의 작업을 Driven Table의 조건을 만족하는 모든 행에 대해 반복 수행한다
- 정렬된 결과를 이용해 조인을 수행하고, 성공하면 추출버퍼에 넣는다
- 정렬할 데이터가 많으면 임시영역(디스크)를 사용하기 때문에 성능이 저하된다
- 인덱스를 사용하지 않아서 인덱스가 존재하지 않을 경우에도 사용이 가능하다
- 비동등 조인에 대해서도 조인 작업이 가능하다
- 스캔 방식을 사용한다
Hash Join
- Hash Join
- 해시 함수를 이용하여 데이터 조인
- 조인을 수행할 테이블의 조인 컬럼을 기준으로 해시 함수를 수행해서 동일한 해시 값을 갖는 것들 중 실제 값이 같은지를 비교하며 조인을 수행
- 이렇게 NL Join의 랜덤 액세스 문제와 Sort Merge Join의 정렬 작업 부담을 해결
- Driving Table에서 주어진 조건을 만족하는 행을 찾는다.
- Driving Table의 조인 키를 기준으로 해시 함수를 적용하여 해시 테이블을 생성한다. 이 때 조인 컬럼과 SELECT 절에서 필요로 하는 컬럼도 함께 저장된다.
- 1~2번 작업을 Driving Table의 조건을 만족하는 모든 행에 대해 반복 수행한다
- Driven Table에서 주어진 조건을 만족하는 행을 찾는다.
- Driven Table의 조인키를 기준으로 해시 함수를 적용하여 해당 버킷을 찾는다
- 조인에 성공하면 추출버퍼에 넣는다. 4~5번 작업을 Driven Table의 조건을 만족하는 모든 행에 대해 반복 수행한다. 장점:
- 조인 컬럼의 인덱스를 사용하지 않는다 > 조인 컬럼의 인덱스가 존재하지 않아도 사용할 수 있다 단점:
- 동등 조인에서만 사용할 수 있다
- 해시 함수를 적용한 값은 기존값을 알 수 없다
- 해시 테이블을 메모리에 생성해야 해서 크기가 크면 임시 영역에 저장해야 한다. (결과 행의 수가 적은 테이블을 Driving Table)로 사용하는 것이 좋다
- 그렇다면 입력한 쿼리에서 어떤 구현 방식을 사용하는지는 어떻게 알 수 있나요?
- 앞 질문들을 통해 인덱스의 중요성을 알 수 있었는데, 그렇다면 JOIN의 성능도 인덱스의 유무의 영향을 받나요?

Leave a comment