
[Database] CS 스터디 2주차
깃허브 인터뷰 레포지토리에 있는 질문들을 가지고 매주 토론하는 스터디를 진행 중입니다.
Key
Key (기본키, 후보키, 슈퍼키 등등…) 에 대해 설명해 주세요.
- 키 (Key)
- 데이터베이스에서 조건에 만족하는 튜플을 찾거나, 순서대로 정렬할 때 튜플들을 서로 구분할 수 있는 기준이 되는 속성을 말함
- 릴레이션 (Relation)
- 관계형 데이터베이스에서 정보를 구분하여 저장하는 기본 단위
- 결국, 릴레이션은 DB 테이블임
- 흔히 개발을 할 때 DB 설계를 하게 되는데, 그것을 ERD라고 함
- ERD의 네모칸 하나하나가 릴레이션임
- 속성 (Attribute)
- 하나의 릴레이션은 현실 세계의 어떤 Entity를 표현하고 저장하는 데 사용됨
- 이때의 Entity는 사물이 될 수도 있고, 추상적인 개념이 될 수도 있음
- 속성이란 내가 저장하고 싶은 Entity의 항목들임
- 하나의 릴레이션은 현실 세계의 어떤 Entity를 표현하고 저장하는 데 사용됨
- 튜플 (Tuple, 레코드)
- 릴레이션의 각 행을 레코드라고 함
- 레코드를 더 공식적으로 튜플이라고 부름
- 후보키 (Candidate Key)
- 후보키는 릴레이션을 구성하는 속성들 중에서 튜플을 유일하게 식별하기 위해 사용하는 속성들의 부분집합, 즉 기본키로 사용할 수 있는 속성들을 말함
- 하나의 릴레이션 내에서는 중복된 튜플이 있을 수 없으므로, 모든 릴레이션에는 반드시 하나 이상의 후보키가 존재함
- 후보키는 릴레이션에 있는 모든 튜플에 대해서 유일성과 최소성을 만족시켜야 함
- 유일성
- 하나의 키값으로 하나의 튜플만을 유일하게 식별할 수 있어야 함
- 최소성
- 모든 레코드들을 유일하게 식별하는 데 꼭 필요한 속성만으로 구성되어 있어야 함
- 유일성
- 기본키 (Primary Key)
- 후보키 중에서 선택한 Main Key
- 한 릴레이션에서 특정 튜플을 유일하게 구별할 수 있는 속성
- Null 값을 가질 수 없음
- 기본키로 정의된 속성에는 동일한 값이 중복되어 저장될 수 없음
- 대체키 (Alternate Key)
- 후보키가 둘 이상일 때, 기본키를 제외한 나머지 후보키들을 말함
- 보조키라고도 함
- 슈퍼키 (Super Key)
- 한 릴레이션 내에 있는 속성들의 집합으로 구성된 키
- 릴레이션을 구성하는 모든 튜플들은 슈퍼키로 구성된 속성의 집합과 동일한 값을 나타내지 않음
- 릴레이션을 구성하는 모든 튜플에 대해 유일성을 만족시키지만, 최소성은 만족시키지 못함
- 최소성
- 학번 + 주민 번호를 사용하여 슈퍼키를 만들면, 다른 튜플들과 구분할 수 있는 유일성은 만족하지만 학번이나 주민 번호 하나만 가지고도 다른 튜플을 구분할 수 있으므로 최소성은 만족시키지 못함
- 최소성
- 한 릴레이션 내에 있는 속성들의 집합으로 구성된 키
- 외래키 (Foregin Key)
- 관계를 맺고 있는 릴레이션 R1, R2에서 릴레이션 R1이 참조하고 있는 릴레이션 R2의 기본키와 같은 R1 릴레이션의 속성
- 참조되는 릴레이션의 기본키와 대응되어 릴레이션 간에 참조 관계를 표현하는 데 중요한 도구
기본키는 수정이 가능한가요?
- 수정은 가능하지만 그것이 unique한 값이어야 함
사실 MySQL의 경우, 기본키를 설정하지 않아도 테이블이 만들어집니다. 어떻게 이게 가능한 걸까요?
- MySQL에서는 테이블을 생성할 때,
기본키를 설정하지 않아도 자체적으로 테이블의 속성 값 중 NULL이 없고, 레코드마다 값이 고유한 첫 속성을 골라 클러스터형 인덱스(PK)로 지정함- GIPK에 따르면 기본키를 새로 생성함
- 만약 테이블에 기본키 또는 적절한 고유 값의 인덱스가 존재하지 않는다면, InnoDB가 자체적으로 클러스터형 인덱스를 생성함
- InnoDB
- MySQL을 위한 데이터베이스 엔진
- InnoDB
- 인덱스 (Index)
- 데이터베이스 테이블의 검색 속도를 향상시키기 위해 사용하고, 시스템 부하를 줄여 시스템 전체 성능 향상에 기여함
- 하지만 인덱스를 위한 추가 공간이 필요하고, 데이터가 많으면 인덱스 생성에 많은 시간이 소요될 수 있다는 단점이 있음
- 데이터베이스 테이블의 검색 속도를 향상시키기 위해 사용하고, 시스템 부하를 줄여 시스템 전체 성능 향상에 기여함
- 클러스터형 인덱스 (Clustered Index, PK)
- 해당 키 값을 기반으로 테이블의 데이터 행을 정렬하고 저장
- 데이터는 오직 하나의 순서로 정렬될 수 있기 때문에 테이블당 최대 한 개만 존재할 수 있음
외래키 값은 NULL이 들어올 수 있나요?
- 가능함
- 예를 들어, 일반 사원은 하나의 부서를 가질 수 있지만, 신입 사원은 부서가 아직 정해지지 않았을 수 있음
어떤 칼럼의 정의에 UNIQUE 키워드가 붙는다고 가정해 봅시다. 이 칼럼을 활용한 쿼리의 성능은 그렇지 않은 것과 비교해서 어떻게 다를까요?
- 처음에 값을 추가할 때는 전체 칼럼을 검색해야 해서 느림 (유일한지 확인하기 위해서)
- 대신에 추후에는 unique 값이 보장되니 빠르게 검색할 수 있음
RDB, NoSQL
RDB와 NoSQL의 차이에 대해 설명해 주세요.
- Database
- 컴퓨터 시스템에 전자 방식으로 저장된 구조화된 정보 또는 데이터의 체계적인 집합을 의미함
- DBMS (Database Management System)
- 사용자와 데이터베이스 사이에서 사용자의 요구에 따라 정보를 생성해주고 데이터베이스를 관리해주는 소프트웨어
- SQL (Structured Query Language)
- RDBMS의 데이터를 관리하기 위해 설계된 특수 목적의 프로그래밍 언어
- RDBMS에서 자료의 검색과 관리, DB 스키마 생성과 수정, 데이터베이스 객체 접근 조정 관리를 위해 고안됨
- RDB (Relactional Database)
- 관계형 데이터 모델에 기초를 둔 데이터베이스로, 데이터의 독립성이 높음
- RDBMS
- 관계형 데이터베이스를 생성하고 수정하는 관리하는 소프트웨어
- NoSQL (Not Only SQL)
- NoSQL는 RDB 형태의 관계형 데이터베이스가 아닌 다른 형태의 데이터 저장 기술을 의미
- RDBMS와 달리 테이블 간 관계를 정의하지 않음
- 그래서 일반적으로 테이블간 Join도 불가능함
- RDBMS와 달리 테이블 간 관계를 정의하지 않음
- 기존의 관계형 데이터베이스의 경우에는 단일 기업의 데이터를 다루는데 최적화 되어 있었음
- 하지만 최신 데이터들은 꼭 관계형으로 처리할 필요가 없는 경우도 많고, 다뤄야 하는 데이터의 양도 훨씬 많이 커짐
- 즉, 빅데이터라고 일컬어 지는 많은 양의 데이터들을 처리하기 위한 방법으로 다양한 해결책이 나왔는데, 그 중 하나가
key-value storage system임key-value storage- SQL을 보통 지원하지 않고, 트랜잭션을 지원하지 않는 SQL을 사용하는 등 SQL을 사용하는 기존의 RDB와 차이점이 있음
- NoSQL는 RDB 형태의 관계형 데이터베이스가 아닌 다른 형태의 데이터 저장 기술을 의미
- RDB vs NoSQL
- 수직적 확장 (Scale-up) vs 수평적 확장 (Scale-out)
- 데이터베이스와 비교하여 NoSQL의 특징은 트랜잭션, ACID를 지원하지 않음
- ACID
- 데이터베이스 내에서 일어나는 하나의 트랜잭션의 안전성을 보장하기 위해 필요한 성질
- RDB는 트랜잭션과 ACID를 보장하기 위해 수평적 확장이 쉽지 않음
- RDB의 경우 multiple server로 수평적 확장을 하게 되면, join을 하기 위해 상당히 복잡한 과정이 필요함
- ACID
- RDB도 수평적 확장이 가능하지만, NoSQL에 비해 훨씬 복잡함
- RDB를 수평적 확장하기 위해선 샤딩(sharding: 데이터가 수평적으로 분할되고 기기의 모음 전반에 걸쳐 분산되는 경우)이 필요
- ACID 준수를 유지하면서 RDB를 샤딩하는 것은 매우 까다로운 작업임
- 데이터베이스와 비교하여 NoSQL의 특징은 트랜잭션, ACID를 지원하지 않음
- NoSQL을 사용하면 좋은 경우
- 정확한 데이터 구조가 정해지지 않은 경우, 데이터 update가 자주 이루어지지 않음
- 조회가 많은 경우, 수평적 확장이 가능하므로 데이터 양이 매우 많은 경우에 사용하면 좋음
- RDB를 사용하면 좋은 경우
- 데이터 구조가 명확하여 변경될 여지가 없는 경우와
- 데이터 중복이 없으므로 데이터 update가 잦은 시스템에서 사용하면 좋음
NoSQL의 강점과, 약점이 무엇인가요?
- RDBMS
- 장점
- 정해진 스키마에 따라 데이터를 저장하여 명확한 데이터 구조를 보장함
- 각 데이터를 중복없이 한 번만 저장할 수 있음
- 단점
- 테이블간 관계를 맺고 있어, 시스템이 커지면 JOIN 문이 많아져 복잡한 쿼리가 필요할 수 있음
- 성능 향상을 위해서는 서버의 성능을 향상시키는 Scale-up이 필요함
- 이때 비용이 기하급수적으로 늘어남
- 장점
- NoSQL
- 특징
- UPDATE/DELETE를 잘 사용하지 않음
- INSERT로 대체함
- 강한 Consistency를 요구하지 않음
- 노드의 추가/삭제 및 데이터 분산에 유연함
- 모델링이 유연함
- 쿼리가 유연함
- UPDATE/DELETE를 잘 사용하지 않음
- 장점
- 스키마가 없어서 유연하고 자유로운 데이터 구조를 가짐
- 언제든지 저장된 데이터를 조정하고 새로운 필드를 추가할 수 있음
- 데이터 분산이 용이함
- 데이터들이 독립적이기 때문
- 성능 향상을 위해 Scale-up과 Scale-out 둘 다 활용이 가능함
- 스키마가 없어서 유연하고 자유로운 데이터 구조를 가짐
- 단점
- 데이터 중복이 발생할 수 있음
- 데이터 무결성, 정합성이 보장되지 않음
- 중복된 데이터가 변경되면 수정을 모든 컬렉션에서 수행해야 함
- 스키마가 없어서 명확한 데이터 구조를 보장할 수 없음
- 특징
RDB의 어떠한 특징 때문에 NoSQL에 비해 부하가 많이 걸릴 수 있을까요?
- 데이블 간에 관계를 맺고 있어, 시스템이 커지면 JOIN 문이 많아지기 때문에 부하가 걸릴 수 있음
NoSQL을 활용한 경험이 있나요? 있다면, 왜 RDB를 선택하지 않고 해당 DB를 선택했는지 설명해 주세요.
- RDBMS의 용도
- 데이터 구조가 명확하고, 변경될 여지가 없으며, 명확한 스키마가 중요한 경우 사용
- RDBMS는 데이터 무결성을 보장하기 때문에 중복된 데이터가 없음
- 즉, 연관된 테이블의 데이터 변경이 용이함
- NoSQL의 용도
- 정확한 데이터 구조를 알 수 없고, 데이터가 변경/확장될 수 있는 경우에 사용
- 데이터 중복이 발생할 수 있고, 중복 데이터 변경 시 모든 컬렉션에서 수정이 필요하니 Update가 많이 일어나지 않는 시스템에서 적합함
- Scale-out이 가능하다는 장점을 활용할 수 있는 경우에도 적합함
트랜잭션, ACID 원칙
트랜잭션이 무엇이고, ACID 원칙에 대해 설명해 주세요.
- Transaction (트랜잭션)
- 데이터베이스의 상태를 변화시키기 위해 수행하는 작업의 단위
- ACID 원칙
- Atomicity (원자성)
- 트랜잭션이 데이터베이스에 모두 반영되거나, 전혀 반영되지 않아야 함
- 트랜잭션 도중에 서버가 다운되는 등과 같은 사건이 발생하면, 트랜잭션은 전혀 반영되지 않은 상태여야 함
- DBMS는 이전에 커밋된 상태를 임시 영역에 따로 저장하고, 현재 수행하고 있는 트랜잭션에 의해 변경된 내역을 유지함
- 현재 수행하고 있는 트랜잭션에서 오류가 발생하면, 현재 변경 내역을 날리고 임시 영역에 저장했던 상태로 롤백함
- Rollback Segment
- 이전 데이터를 임시로 저장하는 영역
- 데이터베이스 테이블
- 현재 수행하고 있는 트랜잭션에 의해 새롭게 변경되는 내역
- Rollback Segment
- 트랜잭션의 원자성은 Rollback Segment에 의해 보장됨
- 트랜잭션의 길이가 길 때는, 오류가 발생하여 처음부터 작업을 수행하는 것을 방지하기 위해 확실한 부분에 대해서는 롤백이 되지 않도록 중간 저장 지점인 save point를 지정할 수 있음
- 이러한 과정을 UNDO 연산이라 부름
- UNDO 연산은 트랜잭션이 정상적으로 종료될 수 없게 되면, 트랜잭션이 변경한 페이지들을 원상 복구시킴
- DBMS는 두 개의 버퍼 관리 정책 중 골라 UNDO를 수행할 수 있는데, STEAL 정책으로 수정된 페이즈를 언제든지 디스크에 쓸 수도 있고, No-STEAL 정책을 통해 수정된 페이즈들을 최소한 트랜잭션 종료 시점까지는 버퍼에 유지할 수도 있음
- 거의 모든 DBMS는 STEAL 정책을 채택해 사용하고, 이는 필연적으로 UNDO 로깅과 복구 작업을 수반함
- No-STEAL 정책은 매우 큰 크기의 메모리 버퍼를 필요로 한다는 단점이 있음
- Consistency (일관성)
- 트랜잭션이 진행되는 동안에 데이터베이스가 변경되더라도 처음에 참조한 데이터베이스로 트랜잭션을 수행
- 업데이트된 데이터베이스는 사용하지 않음
- 그렇기 때문에 사용자는 일관성 있는 데이터를 볼 수 있음
- DBMS는 트랜잭션 전 후에 데이터 모델의 모든 제약 조건을 만족시켜 일관성을 보장함
- 트랜잭션이 진행되는 동안에 데이터베이스가 변경되더라도 처음에 참조한 데이터베이스로 트랜잭션을 수행
- Isolation (고립성)
- 둘 이상의 트랜잭션이 동시에 실행되고 있는 경우, 각각 다른 트랜잭션의 연산에 끼어들 수 없음
- 이 트랜잭션이 완료될 때까지 다른 트랜잭션은 이 트랜잭션의 결과를 참조할 수 없음
- Concurrent Processing(병행 처리)의 경우에 공통된 데이터의 조작 때문에 데이터가 혼란스러워질 수 있어서 독립성 보장이 필수적임
- Lock과 Unlock을 통해 데이터의 고립성을 보장함
- MVVC ?
- 트랜잭션에서 데이터를 읽을 때에는, 여러 트랜잭션이 읽을 수는 있지만 쓸 수 없는
shared_lock을 사용함 - 트랜잭션에서 데이터를 쓸 때는, 다른 트랜잭션이 읽을 수도 쓸 수도 없게 하는
exclusive_lock을 사용함 - 트랜잭션의 읽기/쓰기 작업이 끝나면,
unlock을 통해 다른 트랜잭션이lock을 할 수 있도록 데이터에 대한 잠금을 풂
- Lock을 사용하면 데드락이 발생할 수도 있어서, 2 Phase Locking Protocol(2PL 프로토콜)을 통해 여러 트랜잭션이 공유하고 있는 데이터에 동시 접근할 수 없도록 함
- 2PL 프로토콜은 두 개의 상태(growing phase, shrinking phase)가 가능함
- growing phase
read_lock,write_lock이 발생
- shrinking phase
unlock발생
- 이 둘은 섞이면 안 됨
lock이 모두 수행된 후에unlock이 모두 수행되어야 함
- growing phase
- 둘 이상의 트랜잭션이 동시에 실행되고 있는 경우, 각각 다른 트랜잭션의 연산에 끼어들 수 없음
- Durability (지속성)
- 트랜잭션이 성공적으로 완료됐을 경우, 결과는 영구적으로 반영되어야 함
- 그리고 런타임 오류가 시스템 오류가 발생하더라도 성공적으로 완료됐을 시의 해당 기록은 영구적이어야 함
- 트랜잭션이 성공적으로 완료됐을 경우, 결과는 영구적으로 반영되어야 함
- Atomicity (원자성)
ACID 원칙 중, Durability를 DBMS는 어떻게 보장하나요?
- Redo
- 이미 커밋한 트랜잭션의 수정을 재반영하는 복구 작업
- 수정했던 모든 페이지를 트랜잭션 커밋 시점에 디스크에 반영하는 FORCE 버퍼 관리 정책과, 수정했던 페이지를 트랜잭A션 커밋 시점에 디스크에 반영하지 않는 No-FORCE 정책 중 채택할 수 있음
- FORCE 정책을 따르면 트랙잭션이 커밋되면 디스크 상의 데이터베이스에 변경사항이 반영되기 때문에 REDO 복구작업이 필요 없지만, No-FORCE 정책을 따르면 커밋한 내용이 디스크 상의 데이터베이스에 반영되지 않았을 수도 있기 때문에 반드시 REDO 작업이 필요함
- 거의 모든 DBMS가 No-FORCE 정책을 채택함
트랜잭션을 사용해 본 경험이 있나요? 어떤 경우에 사용할 수 있나요?
- 있음
- 하나의 Entity에 여러 작업이 동시 수행될 가능성이 존재하면 사용하는 것이 좋음
- 스프링에서는 아래와 같이 트랜잭션을 보장할 수 있음
@Transactional(isolation = Isolation.READ_COMMITTED)@Transactional어노테이션에 격리 수준은 옵셔널하게 정의할 수 있음
읽기에는 트랜잭션을 걸지 않아도 될까요?
- 읽기 연산만 일어나면 데이터의 변경이 일어나지 않기 때문에 동시에 읽어도 문제가 생기지 않음
트랜잭션 격리 레벨
트랜잭션 격리 레벨에 대해 설명해 주세요.
- 트랜잭션 격리 수준 (Transaction Isolation Level)
- 동시에 여러 트랜잭션이 처리될 때, 트랜잭션끼리 얼마나 서로 고립되어 있는지를 나타냄
- 즉, 특정 트랜잭션이 다른 트랜잭션에 변경한 데이터를 볼 수 있도록 허용할지를 결정
- 트랜잭션 격리 수준은 트랜잭션 수준 읽기 일관성을 지키기 위해 필요함
- 트랜잭선 수준 읽기 일관성
- 트랜잭션이 시작된 시점부터 일관성 있게 데이터를 읽어오는 것을 의미
- 트랜잭선 수준 읽기 일관성
- 데이터베이스는 Locking을 이용해 트랜잭션의 고립성을 보장하는데, Locking으로 동시에 수행되는 많은 트랜잭션을 순서대로 처리하면 데이터베이스의 성능이 저하될 수 있음
- 하지만 성능을 높이기 위해 Locking의 범위를 줄이면 잘못된 값이 처리될 수도 있음
- 이를 방지하기 위해 효율적인 Locking 방법을 고안하고 있음
- 아래와 같은 트랜잭션 격리 수준이 존재함
Read UncommittedRead CommittedRepeatable ReadSerializable
- 트랜잭션 격리 수준에 따라 발생 가능한 문제점이 아래와 같이 존재함
Dirty Read- 하나의 트랜잭션의 커밋되지 않은 변경사항을 다른 트랜잭션이 접근할 수 있게 되어 그 변경사항이 롤백되는 상황에도 다른 트랜잭션은 자신이 참조한 데이터를 기준으로 로직을 수행하여 데이터 정합성에 문제가 일어날 수 있는 상황
- UNDO 영역을 활용해 커밋되기 전 데이터만을 다른 트랜잭션에게 보여줘서 해결할 수 있음
- SNAPSHOT에 대해 공부해 보기
Non-Repeatable Read- 한 트랜잭션 안에서 같은 쿼리를 두 번 실행했을 때 다른 값이 나오는 Read 현상을 의미
- 특정 데이터에 대한 수정이 발생하여 나타나는 현상으로,
Read Committed수준 이하의 데이터베이스에서 일어날 수 있음
Phantom Read- 한 트랜잭션 안에서 같은 쿼리를 두 번 수행하면, 첫 번째 쿼리에서는 없던 레코드가 두 번째 쿼리에서 발생하는 현상을 의미
Read Uncommitted(레벨 0)- 트랜잭션에 처리 중이거나, 아직 커밋되지 않은 데이터를 다른 트랜잭션이 읽을 수 있는 격리 수준이기 때문에 데이터베이스의 일관성을 유지할 수 없음
- SELECT 문장이 수행되는 동안 해당 데이터에 Shared Lock이 걸리지 않음
- 이 격리 수준에서는 Dirty Read, Non-Repeatable Read, Phantom Read 현상이 발생할 수 있음
- (예) Drity Read
- 트랜잭션 A에서 김수진 학생의 나이를 10에서 11로 바꿨지만 아직 커밋하지 않음
- 트랜잭션 B는 이 시점에 커밋되지 않은 해당 변경사항을 읽고 로직을 수행함
- 트랜잭션 A는 성공적으로 완료하지 못해 데이터를 롤백하지만, 트랜잭션 B는 이미 김수진 학생의 나이를 11로 고려하여 로직을 수행해 데이터 정합성(Consistency) 문제가 발생함
Read Committed(레벨 1)- 트랜잭션이 수행되는 동안 다른 트랜잭션이 접근할 수 없기 때문에 대기함
- SELECT 문장이 수행되는 동안 해당 데이터에 Shared Lock이 걸림
- 커밋이 이루어진 트랜잭션만 조회 가능함
- 이는 Oracle DB, SQL Server에서 기본적으로 사용하는 격리 수준임
- 이 격리 수준에서는 Non-Repeatable Read, Phantom Read 현상이 발생할 수 있음
- (예) Non-Repeatable Read
- 트랜잭션 A가 김수진의 나이를 처음 조회했을 때 10을 얻음
- 이후에 트랜잭션 B가 김수진의 나이를 11로 바꾼 후 커밋하면, 트랜잭션 A가 동일 트랜잭션 내에서 다시 김수진을 조회했을 때 11을 얻음
Repeatable Read(레벨 2)- 트랜잭션이 범위 내에서 조회한 데이터 내용은 항상 동일함을 보장함
- 그래서 다른 사용자는 트랜잭션 영역에 해당하는 데이터에 대한 수정이 불가능함
- SELECT 문장이 사용되는 모든 데이터에 Shared Lock이 걸림
- 이 격리 수준에서는 Phantom Read 현상이 발생할 수 있음
- (예)
Phantom Read- 트랜잭션 A는 읽기 연산을 수행하고, 트랜잭션 B는 쓰기 연산을 수행함
- 트랜잭션 A가 총 N개의 레코드를 읽는 연산을 수행한 후에, 트랜잭션 B가 데이터베이스에 레코드를 추가하면 트랜잭션 A가 다시 레코드를 읽을 때 총
N+1개의 레코드를 읽게 됨
- 트랜잭션이 범위 내에서 조회한 데이터 내용은 항상 동일함을 보장함
Serializable(레벨 3)- 가장 엄격한 격리 수준으로 완벽한 읽기 일관성 모드를 제공함
- 다른 사용자는 트랜잭션 영역에 해당하는 데이터에 대한 수정 및 입력이 불가능함
- 트랜잭션이 완료될 때까지 SELECT 문이 사용되는 모든 데이터에 Shared Lock이 걸림
- 일반적으로 레벨이 높아질수록 트랜잭션 간에 고립 정도가 높아지는 동시에 성능 저하가 일어남
- DBMS는 주로
Read commited(Oracle) 또는Repeatable Read(MySQL)을 지원함
- DBMS는 주로
모든 DBMS가 4개의 레벨을 모두 구현하고 있나요? 그렇지 않다면 그 이유는 무엇일까요?
- Oracle
- Oracle은 기본적으로
Read Committed(레벨 1)을 사용함 Read Committed는 락을 사용하지 않고, 쿼리 시작 시점의 UNDO 데이터를 제공하는 방식으로 구현함Repeatable Read는 명시적으로 구현하지는 않지만,for update절을 이용해 구현이 가능함
- Oracle은 기본적으로
- MySQL
- MySQL의 InnoDB 스토리지 엔진은
Repeatable Read(레벨 2)를 사용함 - InnoDB 스토리지 엔진에서
Repeatable Read를 사용하면 Gap Lock과 Next Key Lock 때문에Phantom Read가 발생하지 않으므로 굳이Serializable을 사용할 필요가 없음 - Record Lock
- 인덱스 레코드에 설정되는 락으로, 테이블에 인덱스가 정의되지 않았어도 InnoDB에서는 숨겨진 클러스터 인덱스를 생성하기 때문에 이를 활용하여 Record Lock을 적용할 수 있음
- (예)
SELECT name FROM test WHERE id = 1 FOR UPDATE;쿼리를 실행하면 id가 1인 레코드에 Record Lock이 설정되어 다른 트랜잭션은 이 레코드를 변경할 수 없음
- Gap Lock
- 갭 자체에 락이 설정되어 삽입하려는 곳의 값 존재 여부와 관계없이 다른 트랜잭션에서 데이터를 삽입할 수 없음
- (예)
SELECT name FROM test WHERE id >= 1 FOR UPDATE;쿼리를 실행하면 id가 1 이상인 모든 레코드에 삽입 작업이 불가능함
- Next-Key Lock
- Record Lock과 해당 인덱스 레코드 앞의 Gap에 대한 Gap Lock이 조합된 락임
Read-Uncommitted는 데이터의 일광성을 보장할 수 없기 때문에 구현하지 않음
- MySQL의 InnoDB 스토리지 엔진은
만약 MySQL을 사용하고 있다면, (InnoDB 기준) Undo 영역과 Redo 영역에 대해 설명해 주세요.
- Undo 영역
- 트랜잭션 실행 후 롤백 시 Undo 로그를 참조하여 이전 데이터로 복구할 수 있도록 로깅한 영역
- Undo 로그는 로그 버퍼에 기록되는데, 이 영역을
Undo Record영역이라 부름 - Undo 로그는 체크포인트에만 디스크에 기록되는데, 너무 긴 트랜잭션이나 무거운 롤백을 주의해야 함
- 하나의 트랜잭션이 너무 길어지면, 그 트랜잭션의 수행 중에 다른 트랜잭션들에 의해 지속적인 체크포인트가 발생하여 Redo/Undo 로그가 지속적으로 쓰여지게 되어 디스크 사용량이 넘칠 수 있음
- 그리고, 롤백은 수많은 Undo 로그 정보를 참조하여 기존의 레코드로 리턴하는 작업이기 때문에 트랜잭션이 길수록 Undo 로그에 쓰인 내용이 많아 롤백 작업은 무거워질 수밖에 없음
- Redo 영역
- 데이터베이스 장애 발생 시 복구에 사용되는 로그로, 버퍼 풀에 저장되어 있던 데이터의 유실을 방지하기 위해 사용됨
- Buffer Pool
- InnoDB 엔진이 테이블 캐싱 및 인덱스 데이터 캐싱을 위해 이용하는 메모리 공간
- 버퍼풀의 메모리 공간이 클수록 캐싱되는 데이터가 늘어나서 디스크에 접근하는 횟수가 줄어들고, DB 성능 향상으로 이어짐
- 하지만 버퍼풀은 메모리 공간이라서 MySQL 장애 발생시 안의 내용은 사라지고, 장애가 복구되더라도 데이터는 복구될 수 없음
- 데이터 변경이 있으면 Redo 로그에 기록하는데, 이는 DML, DDL, TCL 등 데이터 변경이 일어나는 모든 것을 기록한다는 뜻임
- SELECT 문은 데이터를 변경하지 않음
- DML(Data Manipulation Language)
- 정의된 데이터베이스에 입력된 데이터를 조회/수정/삭제
- (예) SELECT, INSERT, UPDATE, DELETE
- DDL(Data Definition Language)
- 데이터베이스를 정의하는 언어
- (예) CREATE, ALTER, DROP, TRUNCATE(테이블 초기화)
- TCL(Transaction Control Language)
- COMMIT, ROLLBACK
- Redo Log Buffer 또한 메모리 영역이기 때문에 장애가 발생하면 사라지고, 용량이 제한적임
- 그래서 체크포인트 이벤트 발생 시점(=log switch)에 Redo Log Buffer의 데이터를 디스크에 파일로 저장하는데, 이를 Redo Log File이라 부르고, 장애 시 복구에 활용함
- 체크포인트 발생 전에 버퍼 풀에 있던 데이터는 유실되지만 마지막 체크포인트 수행 시점까지의 데이터가 Redo 로그 파일로 남아있어 이 파일을 사용해 데이터를 복구할 수 있음
- Redo 로그는 트랜잭션 커밋과 체크포인트에 디스크에 기록된다.
그런데, 스토리지 엔진이 정확히 무엇을 하는 건가요?
- MySQL은 크게 서버 엔진과 스토리지 엔진 두 가지 구조로 구성되어 있음
- 서버 엔진
- 클라이언트의 쿼리 요청을 받아 쿼리 파싱과 스토리지 엔진 데이터를 요청하는 작업을 수행함
- 스토리지 엔진은 물리적 저장 장치에서 데이터를 읽어옴
- 스토리지 엔진
- 서버 엔진과 다르게 여러 개를 동시에 사용할 수 있고, 각 테이블이 사용할 스토리지 엔진을 지정할 수 있음
- 각 스토리지 엔진은 다른 작업 처리 방식을 가져서 성능 차이가 발생하기도 하니 스토리지 엔진의 선택은 매우 중요함
- 테이블의 스토리지 엔진의 종류는 8가지가 있는데, 이 중 InnoDB, MyISAM, Archive가 흔하게 사용됨
- 서버 엔진
- InnoDB
- InnoDB는 디폴드 스토리지 엔진으로 ACID 모델을 따르고, 커밋, 롤백 및 복구 기능을 갖춘 트랜잭션으로 데이터를 보호함
- Buffer Pool의 활용으로 디스크 상의 데이터 파일이나 인덱스 정보를 메모리에 캐시하고 변경된 데이터를 모아서 처리하기 때문에 디스크 I/O 횟수를 줄일 수 있음
- PK를 기반으로 쿼리를 최적화하도록 디스크에 데이터를 정렬하여 저장하는데, 클러스터 인덱스를 활용해 PK 검색에 대한 I/O를 최소화함
- Row-Level Lock과 MVCC(Multi Version Concurrency Control)을 이용해 멀티 유저에게 동시성을 제공함
- 데이터 무결성을 보장하기 위해 외래키를 지원하고, 데이터를 다른 테이블로 분리할 때 참조 무결성을 위한 외래키 설정이 가능함
- 자동으로 데드락을 감지하여, 변경된 레코드가 가장 적은 트랜젝션을 롤백하여 자동으로 데드락을 풂
인덱스
인덱스가 무엇이고, 언제 사용하는지 설명해 주세요.
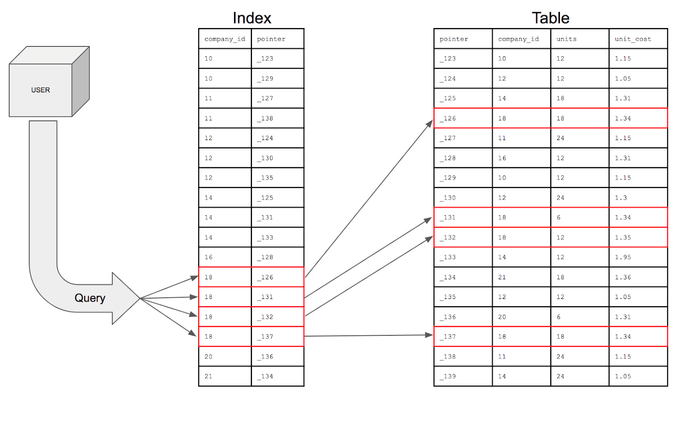
- 추가적인 쓰기 작업과 저장 공간을 활용하여 데이터베이스 테이블의 검색 속도를 향상시키기 위한 자료구조
- 인덱스를 활용하면 데이터 조회/수정/삭제의 성능이 향상됨
- 인덱스를 사용하지 않은 컬럼을 조회하려면 전체를 비교하며 탐색(Full Scan)을 해야 하여 처리 속도가 떨어짐
- 인덱스의 효과를 누리려면 인덱스를 항상 최신의 정렬 상태로 유지해야 하기 때문에, INSERT/UPDATE/DELETE 문으로 인덱스가 적용된 컬럼이 수정되면 연산을 추가적으로 해야 하는 오버헤드가 발생함
- INSERT/DELETE/UPDATE가 빈번하게 발생하는 속성에 인덱스를 걸면 성능이 오히려 저하될 수 있음
- UPDATE와 DELETE는 기존의 인덱스를 삭제하기 않고
사용하지 않음처리를 하여 실제 데이터보다 인덱스가 더 많이 존재하게 될 수 있음- 사용되지 않는 인덱스는 바로 제거해주는 것이 좋음
- 인덱스를 사용하기 적절한 경우
- 규모가 작지 않은 테이블
- INSERT/UPDATE/DELETE 문이 자주 발생하지 않는 컬럼
- 업데이트를 위해서
- JOIN/WHERE/ORDER BY 문에 자주 사용되는 컬럼
- 데이터의 중복이 낮은 컬럼
- 장점
- 테이블을 조회하는 속도와 조회를 사용하는 연산의 성능을 향상시킴
- 전반적인 시스템의 부하를 줄임
- 단점
- 인덱스를 관리하기 위해 DB의 약 10%에 해당하는 저장 공간이 필요함
- 인덱스를 관리하기 위해 추가 작업이 필요함
- 인덱스를 잘못 사용하면 오히려 성능이 저하되는 역효과가 발생할 수 있음
- 인덱스의 자료 구조
- 인덱스는 대표적으로 Hash Table과 B+ Tree로 구현함
- B+ Tree
- 리프 노드(인덱스 노드)만 인덱스와 함께 데이터를 가지고, 나머지 노드(인덱스 노드)는 데이터를 위한 인덱스만 갖음
- 리프 노드는 링크드 리스트로 연결
- 데이터 노드의 크기는 인덱스 노드의 크기가 같지 않아도 됨
- B+ Tree의 리프 노드는 링크드 리스트로 연결되어 부등호를 이용한 순차 검색 연산에 적합함
- 비록 $O(logN)$의 시간 복잡도를 갖지만, 인덱싱에 더 적합함
- InnoDB는 B+ Tree를 더 복잡하게 구현했는데, 같은 레벨의 노드들끼리 이중 링크드 리스트로 연결하고 자식 노드는 단일 링크드 리스트로 구현함
- MYSQL
- 클러스터드 인덱스가 가리킴
일반적으로 인덱스는 수정이 잦은 테이블에선 사용하지 않기를 권합니다. 왜 그럴까요?
- 데이터 삽입 (INSERT)
- 테이블에는 입력 순서대로 저장되지만, 인덱스 테이블에는 정렬하여 저장하기 때문에 성능 저하가 발생함
- 데이터 삭제 (DELETE)
- 테이블에서만 삭제되고, 인덱스 테이블에는 여전히 남아 있어서 쿼리 수행 속도가 저하됨
- 데이터 수정 (UPDATE)
- 인덱스에는 UPDATE가 없기 때문에 DELETE, INSERT 두 작업을 수행하여 부하가 발생함
- 수정이 잦으면 실제 데이터보다 인덱스의 크기가 너무 커져 부하가 발생함
앞 꼬리질문에 대해, 그렇다면 인덱스에서 사용하지 않겠다고 선택한 값은 위 정책을 그대로 따라가나요?
- 몰라
ORDER BY/GROUP BY 연산의 동작 과정을 인덱스의 존재여부와 연관지어서 설명해 주세요.
- 인덱스를 사용하지 않는 ORDER BY
- Filesort 방식으로, 레코드를 읽어온 후 MySQL 서버에서 Sort Buffer라는 메모리 공간을 활용해 정렬함
- Sort Buffer의 크기는 가변적으로 증가하고, 최대 사이즈는 시스템 변수
sort_buffer_size로 설정할 수 있음
- Sort Buffer의 크기는 가변적으로 증가하고, 최대 사이즈는 시스템 변수
- Sort Buffer의 크기보다 큰 레코드 결과를 정렬해야 할 때는 부분적으로 나눠 Sort Buffer에서 정렬을 수행하는데, 잠시 결과를 저장해야 할 테이블로 임시 테이블이 필요함
- 임시 테이블은 메모리 또는 디스크에 생성될 수 있는데, 디스크에 생성됐을 때는 정렬을 위해 메모리에 비해 성능이 훨씬 떨어지는 디스크 I/O가 빈번하게 발생하여 속도가 느려짐
- 쿼리 최적화를 통해 모든 쿼리의 정렬을 인덱스로 하는 것이 좋겠지만, 튜닝이 불가능한 경우가 존재함
- 정렬 기준이 너무 다양해 정렬 기준마다 인덱스를 생성하는 것이 불가능
- UNION과 같이 임시 테이블의 결과를 다시 정렬해야 함
- 정렬 알고리즘
- Single Pass
- SELECT 되는 모든 컬럼을 Sort Buffer에 담아서 정렬을 수행함
- Two Pass
- 정렬 대상 컬럼과 PK 컬럼만 Sort Buffer에 담아서 정렬을 수행한 다음, 정렬 순서대로 PK를 통해 레코드를 읽어옴
- 예전의 방식이지만 Sort Buffer에 모든 컬럼을 담기 어려울 때 이 방법을 사용함
- 정렬 대상 컬럼과 PK 컬럼만 Sort Buffer에 담아서 정렬을 수행한 다음, 정렬 순서대로 PK를 통해 레코드를 읽어옴
- Single Pass
- Filesort 방식으로, 레코드를 읽어온 후 MySQL 서버에서 Sort Buffer라는 메모리 공간을 활용해 정렬함
- 인덱스를 사용하지 않는 GROUP BY
- 인덱스를 사용할 수 없을 때는 임시 테이블을 사용함
- 임시 테이블을 사용하여 처리될 때는 Extra 컬럼에
Using Temporary라는 메시지가 나타남
- 임시 테이블을 사용하여 처리될 때는 Extra 컬럼에
- ORDER BY/GROUP BY 연산에 인덱스를 사용하는 조건
- GROUP BY에 인덱스 사용
- WHERE/ORDER BY/GROUP BY가 인덱스를 사용하려면 기본적으로 인덱스된 컬럼의 값을 변환하지 않고 그대로 사용해야 함
- 임시적인 가공이라도 사용하지 않음
- GROUP BY 절에 명시된 컬럼의 순서가 인덱스를 구성하는 컬럼의 순서와 같으면 인덱스를 이용할 수 있음
- 조건
- GROUP BY 절에 명시된 컬럼이 인덱스 컬럼의 순서와 위치가 같음
- GROUP BY 절에 명시된 컬럼이 하나라도 인덱스에 없으면 인덱스를 사용하지 못함
- 인덱스를 구성하는 컬럼 중에서 뒤쪽에 있는 컬럼은 GROUP BY 절에 명시되어 있지 않아도 인덱스를 사용할 수 있지만 인덱스의 앞쪽에 있는 컬럼이 GROUP BY 절에 명시되지 않으면 인덱스를 사용할 수 없음
- WHERE/ORDER BY/GROUP BY가 인덱스를 사용하려면 기본적으로 인덱스된 컬럼의 값을 변환하지 않고 그대로 사용해야 함
- ORDER BY에 인덱스 사용
- ORDER BY는 GROUP BY의 조건에 조건을 더 추가함
- 정렬되는 각 컬럼의 오름차순 및 내림차순 옵션이 인덱스와 같거나 또는 정반대의 경우에만 사용할 수 있음
- ORDER BY 절의 모든 컬럼이 오름차순이거나 내림차순일 때만 인덱스를 사용할 수 있음
- 인덱스에 정의된 컬럼의 앞쪽부터 일치해야 함
- ORDER BY는 GROUP BY의 조건에 조건을 더 추가함
- GROUP BY에 인덱스 사용
- 인덱스를 사용할 수 없을 때는 임시 테이블을 사용함
- 인덱스를 사용한 ORDER BY/GROUP BY
- 인덱스가 있다는 것은 인덱스 컬럼을 기준으로 정렬되어 있다는 뜻임
- 별도의 정렬을 위한 처리가 필요 없어, 성능적으로 우수함
기본키는 인덱스라고 할 수 있을까요? 그렇지 않다면, 인덱스와 기본키는 어떤 차이가 있나요?
- MySQL
- 일반적으로 DBMS에서 PK의 인덱스가 자동으로 적용되지만, PK와 인덱스는 같지 않음
- PK는 개념적인 값으로 레코드의 유일성을 보장하지만, 물리적으로는 저장되지 않음, 논리적 개념임
- 반면에 인덱스는 레코드의 유일성은 보장하지 않고, 단지 탐색을 빠르게 해주는 역할을 함
- 별도의 디스크 공간에 저장됨
그렇다면 외래키는요?
- 기본키와 같음

{kind=link}
Leave a comment